

Introduction
Installing an application, especially a third-party application, is not usually a major problem, and updating can be made easier by choosing a containerized installation and using Docker Compose, for example. But sticking to manual tasks for deployments, updates and configuration changes can become burdensome and error-prone, especially if a rollback is required from an unversioned configuration.
On the other hand, when we only have to manage a handful of containers for an application deployed on a simple VM infrastructure (which happens more often than we think :-)), we don’t really need to push a Kubernetes configuration that will essentially increase maintenance costs and the learning curve for newcomers.
Ansible offers the possibility of controlling the configuration of an application on a given infrastructure and several environments, and especially the deployment of Docker Compose to manage the launch of the containers that make it up. Gitlab is a source code management (SCM) interface that lets you configure the CI/CD part (continuous integration/continuous deployment).
We will take a look at the deployment use case for this site to see how to make precise use of these tools to achieve deployments that are both safe and fast.
Defining the use case
In this article, we will consider the deployment of this website, delivered as a gazerad/mywebsite container on Docker hub, along with an accompanying Grafana/Prometheus/Node exporter monitoring solution, all behind a Nginx reverse Proxy handling certificates and incoming traffic.
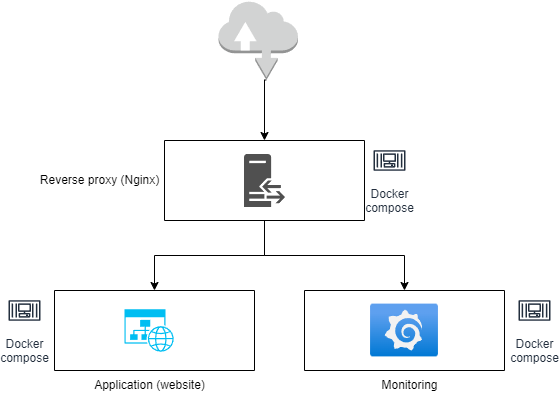
This deployment is to be carried out on two environments:
- INT: a server deployed on the local network, using self-signed certificates.
- PROD: an AWS EC2 server, using certificates provided by let’s encrypt.
We’d like to get an installation process where :
- Configuration is managed as code in a project published on an SCM.
- Configuration is generated dynamically for a set of environments (here INT and PROD).
- Deployments are triggered by push/tag events on the SCM tool, then launched manually from the SCM interface for the production environment.
- No user access is required on the infrastructure to be deployed, since no manual commands need be executed.
This is the ideal situation for using Ansible to manage configuration, statically and dynamically, for deployment across a range of servers/environments. Gitlab is also a logical choice as an SCM tool that can also automate tasks triggered by SCM events by defining pipelines.
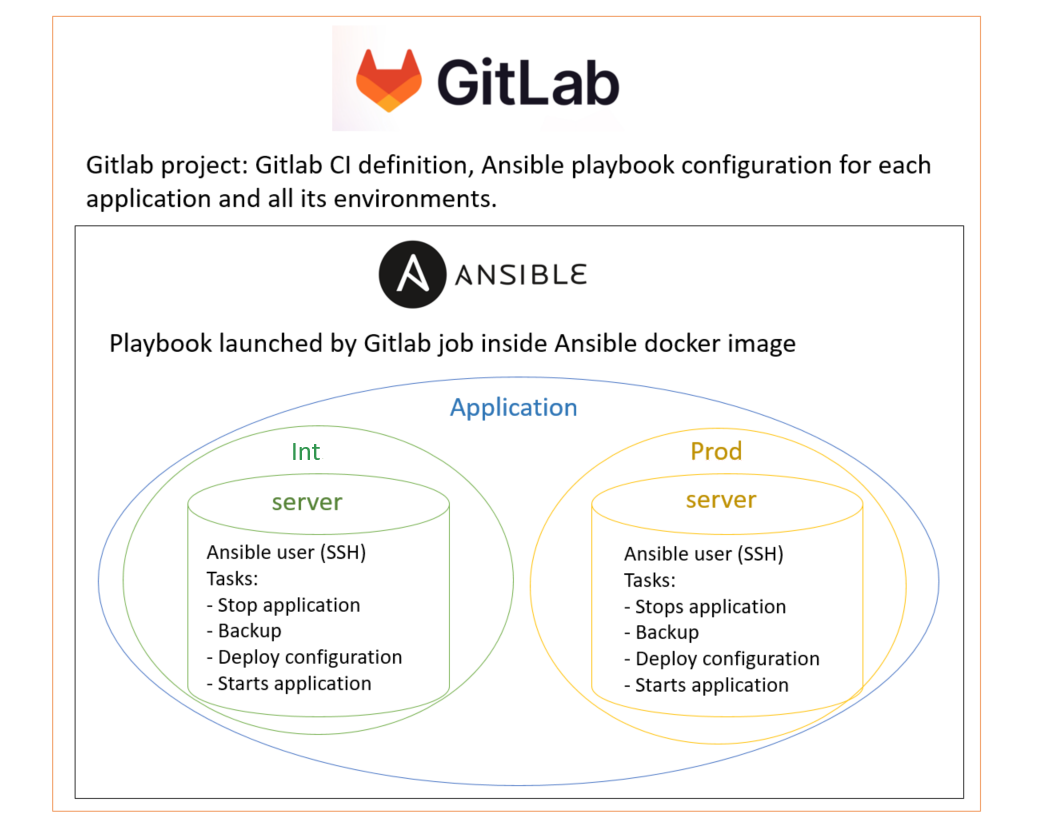
In this way, we can :
- ensure that the configuration is saved and versioned, making the previous configuration immediately available and deployable in the event of a roll-back
- minimize user access to the infrastructure for manual tasks.
As a result, we can improve the security and efficiency of CI/CD processes by being able to rapidly deploy precisely what we want.
In the remainder of this article, we will consider the Website Core project corresponding to the backend/frontend code of this site, where the Ansible deployment is defined in the deployments/ansible directory.
We will consider that Docker has already been installed on the target servers.
Configuring Ansible and the Gitlab project
Generate the SSH key pair used by Ansible
Ansible relies on SSH to perform deployments on the servers associated with each environment of a given application. Therefore, for each of these servers, we need to generate an SSH key pair that will be recognized by the Ansible user to perform the deployment.
It doesn’t matter which server the SSH key pair is located on. For practical purposes, we’ll name each key as follows: ansible_[application name]_[environment]
Below is the command to be run on any server to generate the SSH key.
ssh-keygen -t ed25519
We have chosen an empty passphrase because it makes deployment harder to automate if there is one, and requires manual entry of a sensitive password.
Generating public/private ed25519 key pair.
Enter file in which to save the key (~/.ssh/id_ed25519): ~/.ssh/ansible_[application name]_[environment]
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in ~/.ssh/ansible_app_env.
Your public key has been saved in ~/.ssh/ansible_app_env.pub.
The key fingerprint is:
SHA256:/dBKUd8TExQDWoxpNTKt8xesipzAbscR9wtINJg2t9I root@SR-F1-GITRUN2
The key's randomart image is:
+--[ED25519 256]--+
| o oB=oBo|
| = + ==+..+|
| . = =.. o..|
| . E * o.|
| . S B = . .|
| o + = + . |
| . + = + o |
| o * . . |
| . . |
+----[SHA256]-----+
Now we have the private/public SSH key pair available:
~/.ssh/ansible_[application name]_[environment]~/.ssh/ansible_[application name]_[environment].pub
For example, for our case and the integration environment :
~/.ssh/ansible_mywebsite_int~/.ssh/ansible_mywebsite_int.pub
Convert SSH key pair to base64 format
In order to be added as Gitlab project variables, we need to convert the keys to a one-line string, so we use base64 encoding for this.
From the previously generated key pair :
APPLICATION= # Put application name here
ENVIRONMENT= # Name of the environment
# Each time, we save the generated string
cat ~/.ssh/ansible_${APPLICATION}_${ENVIRONMENT} | base64 -w 0
cat ~/.ssh/ansible_${APPLICATION}_${ENVIRONMENT}.pub | base64 -w 0
Add encoded SSH keys to Gitlab project variables
We will now need to edit the CI/CD parameters of our Gitlab project in order to add the encoded keys as variables.
Please first note that in our case, variable names must follow the following rule, for a given APPLICATION application and ENVIRONMENT environment (each in upper case):
[APPLICATION]_[ENVIRONNEMENT]_SSH_PRIVATE_KEY_BASE64
[APPLICATION]_[ENVIRONNEMENT]_SSH_PUBLIC_KEY_BASE64
For example, with Mywebsite application and int environment:
- Private key:
MYWEBSITE_INT_SSH_PRIVATE_KEY_BASE64 - Public key:
MYWEBSITE_INT_SSH_PUBLIC_KEY_BASE64
Next, we fill these variables with the following characteristics (described here), depending on the environment:
- prod: protects and hides the variable
- int: hides only the variable
Set Ansible Vault passwords as Gitlab variables
Ansible Vault is used to encrypt sensitive content (passwords, SSH private keys) so that it can be safely stored in collaborative tools such as a SCM (in our case, the Gitlab project).
To do this, we need a master password that will allow us to decrypt the vaulted content. In our case, as we have two environments, we will choose two Vault passwords to encrypt sensitive variables in each of the two environments. Logically, these cannot be published directly in the Gitlab project.
We don’t really need to juggle between these Vault passwords since their use will be limited to the Gitlab CI/CD pipelines, so there will be no need to use the Vault IDs feature.
We will therefore define two Vault passwords that will be stored as Gitlab variables of the project:
- prod :
ANSIBLE_VAULT_PASSWORD_PROD - int :
ANSIBLE_VAULT_PASSWORD_INT
In the same way as above, these variables will have the following characteristics:
- prod : protects and hides the variable
- int : only hides the variable
Encrypt passwords with Ansible Vault
Using the Vault passwords that we have just generated, we will now be able to encrypt our application sensitive data.
These can then be added, once encrypted, in the vault.yml file of the inventory corresponding to the environment considered.
To encrypt a password, proceed as follows, using the Vault password of the environment (INT or PROD).
# Open the .vault_pass file and enter the vault password
vi .vault_pass
# Set environment variable ANSIBLE_VAULT_PASSWORD_FILE
export ANSIBLE_VAULT_PASSWORD_FILE=./.vault_pass
# Password encryption
ansible-vault encrypt_string 'mon_mot_de_passe'
We get the encypted password :
Encryption successful
!vault |
$ANSIBLE_VAULT;1.1;AES256
30386565656261343265343138663433643837366132616566653239396635323565643931373035
3261386338353031323633663835313332346466386162660a383761393130633562633132313839
64613162373531643064646233613062316336616632356162623536386437396538306136616136
3035396131353636350a376338353461643136363135613762623039623031313562623365336265
30656464316461313638326636646563306464663962626432316631626130353765316231626566
6463306337623163306339303438653163366331343439626534
Configure the ansible user on the target servers
Ansible needs a user with the following characteristics on the target servers:
- sudo rights
- no password: otherwise, automation becomes difficult to manage without any essential security benefit
- on all commands: limiting the scope of sudo commands is discouraged by the official documentation since Ansible encapsulates commands with Python and executes many more than those defined in the playbook.
- no user password : for security reasons, only SSH key authentication is allowed.
You therefore need to run the following commands with a user who has sufficient sudo rights:
# Create the ansible user with sudo rights to all commands
sudo useradd -m ansible -s /bin/bash
sudo usermod -aG sudo ansible
echo "ansible ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ansible
# Remove password authentication
sudo passwd -l ansible
Now we are going to add the previously generated public key to the configuration of the ansible user we have just created.
To do this, run the following commands while logged in as the ansible user:
# Run as the ansible user
mkdir -p ~/.ssh
echo "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" | tee -a ~/.ssh/authorized_keys
Depending on the playbook that will be run, you might have to install additional libraries with pip.
Definition of the Ansible deployment playbook
The aim of the playbook is to deploy the site and the monitoring solution behind a Nginx reverse proxy.
Organization of playbook content
In accordance with Ansible best practices, we have defined the contents of the deployment playbook in the deployments/ansible directory of the Gitlab project as follows.
├── inventories
│ ├── 000_cross_env_vars.yml
│ ├── 001_versions.yml
│ ├── int
│ │ ├── group_vars
│ │ │ └── all
│ │ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ │ ├── vars.yml
│ │ │ └── vault.yml
│ │ └── hosts
│ └── prod
│ ├── group_vars
│ │ └── all
│ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ ├── vars.yml
│ │ └── vault.yml
│ └── hosts
├── roles
│ ├── application
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── monitoring
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── reverse_proxy
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ └── server
│ ├── defaults
│ ├── files
│ ├── handlers
│ ├── meta
│ ├── tasks
│ ├── templates
│ └── vars
├── playbook-deploy.yml
└── playbook-setup.yml
There are 3 main categories, which we will detail later:
- inventories: under the
inventoriesdirectory, define the contents of theintandprodenvironments in our case, such as the list of target servers (hosts), variables common or specific to each inventory etc. - roles: under the
rolesdirectory are grouped by logical configuration element (application, server, reverse proxy, …) everything that will enable the execution of related tasks in a playbook, i.e. files/templates to be deployed, task definitions, specific variables, etc. - playbooks: located at the root of the directory, these are files that group together the tasks/roles to be executed according to the desired case.
Inventories: general variable configuration
├── inventories
│ ├── 000_cross_env_vars.yml
│ ├── 001_versions.yml
│ ├── int
│ │ ├── group_vars
│ │ │ └── all
│ │ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ │ ├── vars.yml
│ │ │ └── vault.yml
│ │ └── hosts
│ └── prod
│ ├── group_vars
│ │ └── all
│ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ ├── vars.yml
│ │ └── vault.yml
│ └── hosts
So that the playbook code can run on different host/variable sets depending on the chosen environment, we need to define an inventory.
The inventory is defined by a set of folders/subfolders in the inventories folder.
Environment configuration
Both environments, int and prod, have the same tree structure which follows the suggested practices.
group_vars/all: contains the definition of variables required by the environment. The name of the
all/folder indicates that these variables apply to each group of hosts defined in thehostsfile, which we will expose later. Here, we can see that we have the following contents:- vars.yml : contains environment-specific variables.
# Websites fqdn mywebsite_fqdn: gazerad.com mywebsite_fr_fqdn: gazerad.fr grafana_fqdn: grafana.mywebsite.com prometheus_fqdn: prometheus.mywebsite.com # Certificates configuration monitoring_cert_name: monitoring # let's encrypt variables lets_encrypt_use: true mywebsite_email: guillaume.azerad@gap-cs.com- vault.yml: contains “vaulted” variables, which are passwords encrypted with Ansible vault. The data can thus be published on Gitlab, as they are indeed encrypted.
vault_mywebsite_password: !vault | $ANSIBLE_VAULT;1.1;AES25 30386565656261343265343138663433643837366132616566653239396635323565643931373035 3261386338353031323633663835313332346466386162660a383761393130633562633132313839 64613162373531643064646233613062316336616632356162623536386437396538306136616136 3035396131353636350a376338353461643136363135613762623039623031313562623365336265 30656464316461313638326636646563306464663962626432316631626130353765316231626566 6463306337623163306339303438653163366331343439626534- symbolic links: these refer to files containing variables which have the same values in all environments.
hosts: this file contains the definition of servers (hosts) for the selected application and environment. First, you must indicate the name of the server group (
[application]here), then list on the same line :- the server name that will be used into the playbook tasks (
mywebsite_debianandmywebsite_ubuntuhere) - the FQDN or IP address of the remote host (variable
ansible_host) - the user name Ansible will use to connect to the server and run the playbook (variable
ansible_user)
- the server name that will be used into the playbook tasks (
We can also define many other variables like
ansible_portto define an alternate ssh port that Ansible will have to use to connect to the server.
As previously stated, we have two servers defined for INT environment and they are identified by a name indicated at the beginning of their definition.
[application]
mywebsite_debian ansible_host=gazerad-int.com ansible_user=ansible
mywebsite_ubuntu ansible_host=gazerad-int2.com ansible_user=ansible
We have chosen the
.iniformat for this file, but it could have been written in YAML, as Ansible accepts both formats for defining playbook configuration.
Global configuration
We also have two files containing identical variable definitions for all environments. As explained above, they are replicated in each environment configuration by a symbolic link.
- 000_cross_env_vars.yml: simply contains variable definitions that apply to all environments. Ideally, this should be limited to general data defining specific values (FQDN, URL, user name, etc.). Other variables more specific to each configuration item should be defined in the corresponding roles.
IMPORTANT: there’s a section that applies “vaulted” variables to another variable name. This was done to avoid filling this file with “vaulted” passwords, which would have made it difficult to read.
# Passwords and keys
mywebsite_password: "{{ vault_mywebsite_password }}"
grafana_admin_password: "{{ vault_grafana_admin_password }}"
external_website_data_access_token: "{{ vault_external_projet_access_token }}"
# gitlab.com website-data project configuration
external_gitlab_api_v4_url: "https://gitlab.com/api/v4"
external_website_data_id: 55398930
# General paths on the server
application_dir: /srv/web
reverse_proxy_dir: /srv/reverse_proxy
monitoring_dir: /srv/monitoring
# Usernames for applications
grafana_user: gazerad
- 001_versions.yml: essentially contains the versions of the services defined in the docker compose files. This is the file that needs to be modified for a service version update. It also contains versions of packages to be installed on servers (here:
docker: 26.0.0).
versions:
docker: 26.0.0
nginx: 1.25.4
certbot: v2.10.0
autoheal: 1.2.0
grafana: 10.4.1
prometheus: v2.51.0
node_exporter: v1.7.0
Role definition
├── roles
│ ├── application
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── monitoring
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── reverse_proxy
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ └── server
│ ├── defaults
│ ├── files
│ ├── handlers
│ ├── meta
│ ├── tasks
│ ├── templates
│ └── vars
As explained above, each role corresponds to an element of the configuration deployed by playbook-deploy.yml playbook.
- application : the containerized website
- monitoring : the Grafana-Prometheus-Node monitoring solution.
- reverse_proxy : the Nginx reverse proxy, which manages certificates and routes incoming traffic to the desired endpoint.
In each case, we are going to deploy a Docker Compose file containing services definition for each role, and they will be included into reverse_proxy Docker compose file that will centralize and run the services making up the deployed application in the background.
The server role is used by the playbook-setup.yml playbook, which handles the configuration of target servers (installation of Debian packages, Docker, etc.). which we will not detail here.
Since all roles have the same structure, we’ll focus on the reverse_proxy role to describe its contents.
├── reverse_proxy
│ ├── defaults
│ │ └── main.yml
│ ├── files
│ │ └── certs
│ │ ├── application
│ │ │ ├── gazerad.crt
│ │ │ ├── gazerad-int.crt
│ │ │ ├── gazerad-int.key.vault
│ │ │ └── gazerad.key.vault
│ │ └── monitoring
│ │ ├── monitoring.crt
│ │ ├── monitoring-int.crt
│ │ ├── monitoring-int.key.vault
│ │ └── monitoring.key.vault
│ ├── handlers
│ │ └── main.yml
│ ├── meta
│ │ └── main.yml
│ ├── tasks
│ │ ├── common_certs.yml
│ │ ├── le_certs.yml
│ │ └── main.yml
│ ├── templates
│ │ ├── docker-compose-le-init.yml.j2
│ │ ├── docker-compose-le.yml.j2
│ │ ├── docker-compose.yml.j2
│ │ ├── nginx
│ │ │ ├── application.conf.j2
│ │ │ └── monitoring.conf.j2
│ │ └── systemd
│ │ ├── renew-certs.service.j2
│ │ └── renew-certs.timer.j2
│ └── vars
│ ├── common_certs.yml
│ └── le_certs.yml
- defaults: this directory contains the definition of default values for role-specific variables. Its contents are automatically read by Ansible when a playbook is run, so there is no need to specifically include the component files. Note the use of the Jinja2
{{ varname }}structure to retrieve the value of a previously defined variable.
# Nginx configuration
nginx_dir: "{{ reverse_proxy_dir }}/nginx"
nginx_conf_dir: "{{ reverse_proxy_dir }}/nginx/conf"
nginx_mywebsite_path: "{{ nginx_conf_dir }}/mywebsite.conf"
nginx_monitoring_path: "{{ nginx_conf_dir }}/monitoring.conf"
files: this directory contains files (configuration or other) that will be deployed as is, without modification, by the playbook.
handlers: here we have the handlers used to trigger events after a task has reached
changedstatus. By default, handlers are executed at the end of the playbook, but it is possible to force them to be launched immediately after a task. It is generally useful to define service stop-start events, which can also be called by other roles in the event of dependency.
- name: Stop docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: absent
become_user: mywebsite
- name: Start docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: present
become_user: mywebsite
- name: Restart docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: restarted
become_user: mywebsite
- meta: this section is dedicated to the role’s metadata. It is especially useful to fill it in when we wish to publish the role on Ansible Galaxy. In our case, we will just indicate dependencies on Ansible Galaxy modules.
collections:
- ansible.builtin
- community.docker
- community.general
tasks: this directory contains the definition of tasks that will be executed by the playbook into which the role is imported. The file main.yml is automatically read when the role is imported; we also see two files common_certs.yml and le_certs.yml which are directly mentioned in the main.yml with the
import_tasksdirective.templates: here we have files deployed on the target servers, but unlike the files directory, they contain variabilized parts in Jinja2
{{ varname }}form, which will be filled in during task execution. For example, for the Docker Compose file below:
# {{ ansible_managed | comment }}
include:
- {{ application_dir }}/docker-compose.yml
- {{ monitoring_dir }}/docker-compose.yml
services:
reverse_proxy:
image: nginx:{{ versions.nginx }}
container_name: reverse_proxy
restart: always
networks:
- frontend
- monitoring
ports:
- 80:80
- 443:443
volumes:
- "{{ nginx_mywebsite_path }}:/etc/nginx/conf.d/mywebsite.conf:ro"
- "{{ nginx_monitoring_path }}:/etc/nginx/conf.d/monitoring.conf:ro"
- "{{ nginx_certs_dir }}:{{ nginx_container_certs_dir }}:ro"
- "{{ nginx_log_dir }}:/var/log/nginx"
- /etc/localtime:/etc/localtime:ro
{% if lets_encrypt_use %}
# Manage certificates generated by let's encrypt
- certs:/etc/letsencrypt
{% endif %}
# DEPRECATED : import CA certificates from the server into the nginx container
# - /etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt:ro
healthcheck:
test: ["CMD", "curl", "-f", "localhost"]
interval: 30s
timeout: 10s
retries: 3
labels:
autoheal: true
networks:
frontend:
monitoring:
{% if lets_encrypt_use %}
volumes:
certs:
name: letsencrypt
external: true
{% endif %}
- vars: this section contains definitions of variables that are more specific than those in the defaults section, and which might overload these ones. In our case, we needed to conditionally define variables (which in this case depend on the value of a variable defined in the inventory), so we created two files that will be included in tasks in this way:
- name: Include related variables
include_vars:
file: le_certs.yml
Playbook definition
├── playbook-deploy.yml
Finally, the playbook playbook-deploy.yml orchestrates the roles in order to execute the application deployment on the selected inventory.
In our case, we have defined a single playbook that executes the roles one after the other, which means that the handlers triggered in each role are only executed at the end of the complete playbook.
- name: Applicative deployment playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: application
tags:
- application
- role: monitoring
tags:
- monitoring
- role: reverse_proxy
tags:
- application
- monitoring
- reverse_proxy
If we had wanted to trigger the handlers at the end of the tasks for each role, we would have had to define three “sub-playbooks” corresponding to each of them.
- name: Deploy application playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: application
tags:
- application
- name: Deploy monitoring playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: monitoring
tags:
- monitoring
- name: Deploy reverse proxy playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: reverse_proxy
tags:
- application
- monitoring
- reverse_proxy
Let’s note a few points:
tags: roles are assigned a list of tags, allowing the playbook to be run for only certain tasks and not all of them. For example, if I only want to deploy the integration application, I’ll add theapplicationtag to the playbook execution command, which will run theapplicationandreverse_proxyroles.
ansible-playbook -i inventories/int --tags application playbook-deploy.yml
hosts: here we refer to the hosts file of the inventory, giving the name of the list of servers on which the playbook will be run.become: true: this indicates that theansibleuser who will run the playbook on the target servers will havesudorights, which will be useful for “becoming” another user on the server (in our case, themywebsiteuser).gather_facts: true: this is the default value for determining whether the playbook retrieves facts. We’ve specified the directive so that we can easily change it tofalseif we feel we no longer need the facts.
Gitlab CI deployment pipeline
We will now describe how to use Gitlab CI and its automatically triggered pipelines to deploy our application using the Ansible playbook described above.
Pipeline execution workflow
The Gitlab Website Core project has a CI/CD pipeline that builds the application and publishes the Docker image to Docker Hub.
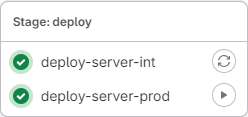
We will simply add a deploy step at the end of the pipeline to ensure deployment on the integration and production environments, following these guidelines:
- A job will be defined in the
deploystep for each environment:deploy-server-intanddeploy-server-prod. - The
deploy-server-intjob will be run automatically, whiledeploy-server-prodwill be run manually. deploy-server-proddepends on the proper execution ofdeploy-server-int. In the event of an error, its launch will be blocked.- The trigger events that will add these jobs to the pipeline are :
deploy-server-int: a release candidate tag (X.X.X-rcXwhere X is a native integer) or a release tag (X.X.X)deploy-server-prod: a release tag (X.X.X), and execution will be manual.
When the conditions have been met to add the deployment to the pipeline, the deploy step will be displayed in the Gitlab pipelines menu as follows:
Gitlab CI code
The .gitlab-ci.yml file in the Website Core project applies the previous execution flow in the deploy step.
Below, we will describe the contents of the deployment jobs that run the Ansible playbook.
variables:
...
ANSIBLE_VERSION: !reference [ .dependencies, images, ansible ]
stages:
...
- deploy
.rules:
# Manages CI/CD process for release and release candidate tagging events
tag_release:
- if: $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+$/ && $DEPLOY_MODE != "Y"
variables:
RELEASE_TYPE: "release"
tag_release_candidate:
- if: $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+-rc\d+$/ && $DEPLOY_MODE != "Y"
variables:
RELEASE_TYPE: "release_candidate"
# Only deploy an existing tagged package from web pipelines
deploy_release:
- if: $CI_PIPELINE_SOURCE == "web" && $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+$/ && $DEPLOY_MODE == "Y"
variables:
RELEASE_TYPE: "release"
deploy_release_candidate:
- if: $CI_PIPELINE_SOURCE == "web" && $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+-rc\d+$/ && $DEPLOY_MODE == "Y"
variables:
RELEASE_TYPE: "release_candidate"
...
...
# Job to manage the deployment of the application to a Linux server with Ansible
deploy-server-int:
stage: deploy
image: ${CI_DEPENDENCY_PROXY_GROUP_IMAGE_PREFIX}/cytopia/ansible:$ANSIBLE_VERSION
rules:
- !reference [.rules, tag_release_candidate]
- !reference [.rules, tag_release]
- !reference [.rules, deploy_release_candidate]
- !reference [.rules, deploy_release]
variables:
ANSIBLE_FORCE_COLOR: 'true' # get Ansible colors displayed on Gitlab UI
APP_NAME: mywebsite
ENV: int
MYWEBSITE_VERSION: $CI_COMMIT_TAG
before_script:
# To resolve potential timeouts on my home network
- echo -e "\nnameserver 1.1.1.1" >> /etc/resolv.conf
script:
- echo "INFO - Application to be deployed is $APP_NAME"
- if [ "X$ENV" == "X" ]; then ENV=$(echo "$CI_JOB_NAME" | awk -F "_|-" '{print $NF}'); fi
- echo "INFO - Environment is $ENV"
# We expect SSH key variables to match the following name : ${APP_NAME}_${ENV}_SSH_(PRIVATE|PUBLIC)_KEY_BASE64
- SSH_PRIVATE_KEY_BASE64_VARNAME=$(echo "${APP_NAME}_${ENV}_SSH_PRIVATE_KEY_BASE64" | tr '[:lower:]' '[:upper:]')
- eval "SSH_PRIVATE_KEY_BASE64=\${$SSH_PRIVATE_KEY_BASE64_VARNAME}"
- SSH_PUBLIC_KEY_BASE64_VARNAME=$(echo "${APP_NAME}_${ENV}_SSH_PUBLIC_KEY_BASE64" | tr '[:lower:]' '[:upper:]')
- eval "SSH_PUBLIC_KEY_BASE64=\${$SSH_PUBLIC_KEY_BASE64_VARNAME}"
# Test if required variables are filled
- |-
if [ "X$APP_NAME" == "X" ] || [ "X$ENV" == "X" ] || [ "X$SSH_PRIVATE_KEY_BASE64" == "X" ] || [ "X$SSH_PUBLIC_KEY_BASE64" == "X" ]
then
echo "ERROR - One of the required variable was missing. Please check your configuration."
exit 1
fi
# Setup SSH key pair that will be used to authenticate against target server
- echo "INFO - Adding SSH key pair provided by Gitlab project variables to local SSH configuration"
- mkdir -p ~/.ssh
- echo "$SSH_PRIVATE_KEY_BASE64" | base64 -d > ~/.ssh/id_ed25519
- chmod 600 ~/.ssh/id_ed25519
- echo "$SSH_PUBLIC_KEY_BASE64" | base64 -d > ~/.ssh/id_ed25519.pub
# Add target host fingerprint to local known_hosts
# We consider here potentially multiple hosts related to the application (not the current use case though)
- APPLICATION_SERVER_FQDN_LIST=$(grep $APP_NAME deployments/ansible/inventories/${ENV}/hosts | awk 'BEGIN{RS=" "; FS="ansible_host="}NF>1{print $NF}')
- echo "INFO - Adding host fingerprints to local known_host for $APP_NAME application servers FQDN list ($ENV environment) - $(echo $APPLICATION_SERVER_FQDN_LIST)"
- |-
for APPLICATION_SERVER_FQDN in $APPLICATION_SERVER_FQDN_LIST; do
# If we are in integration, we edit /etc/hosts to add the IP address of the target server
if [ "$ENV" == "int" ]; then
IP_ADDR_VARNAME=$(echo "${APP_NAME}_${ENV}_IP_ADDR" | tr '[:lower:]' '[:upper:]')
eval "IP_ADDR=\${$IP_ADDR_VARNAME}"
echo -e "\n$IP_ADDR $APPLICATION_SERVER_FQDN" >> /etc/hosts
fi
ssh-keyscan -H $APPLICATION_SERVER_FQDN >> ~/.ssh/known_hosts
done
# Go to ansible deployments folder
- cd $CI_PROJECT_DIR/deployments/ansible
# Setup Ansible vault configuration
- echo "INFO - Setting up Ansible vault configuration"
- ANSIBLE_VAULT_PASSWORD_VARNAME=$(echo "ANSIBLE_VAULT_PASSWORD_${ENV}" | tr '[:lower:]' '[:upper:]')
- eval "ANSIBLE_VAULT_PASSWORD=\${$ANSIBLE_VAULT_PASSWORD_VARNAME}"
- echo "$ANSIBLE_VAULT_PASSWORD" > .vault_pass
- export ANSIBLE_VAULT_PASSWORD_FILE=./.vault_pass
# Launch the Ansible playbook
- ansible-playbook -i inventories/$ENV playbook-deploy.yml
# Deployment to prod server
deploy-server-prod:
extends: deploy-server-int
rules:
- !reference [.rules, tag_release]
- !reference [.rules, deploy_release]
variables:
ENV: prod
when: manual
needs: [ "deploy-server-int" ]
To summarize, the steps in the deployment job are as follows:
- Retrieve the SSH keys from the Gitlab project variables and according to the application/environment pairing (
mywebsite/intormywebsite/prodhere) - Modification of the ssh configuration of the container in which the job is run, so that the keys can be used directly.
- Adding the fingerprint of the server(s) on which you’re deploying. This is essential so that no confirmation is requested when the playbook is run.
- Installation of the Ansible Vault configuration: this involves retrieving the Vault password corresponding to the given environment from the Gitlab project variables, and writing it to a
.vault_passfile in the playbook location. - Running the
playbook-deploy.ymlplaybook with the inventory of the given environment
We can also see that :
- Jobs are run in a container created from the image cytopia/ansible, which provides a containerized version of Ansible.
- The
ANSIBLE_FORCE_COLOR: 'true'variable is used to display “Ansible” colors in the job execution log. - The
deploy-server-prodjob is simply an extension of thedeploy-server-intjob, with the redefinition of a few variables. - This same
deploy-server-prodjob depends on thedeploy-server-intjob, even though it belongs to the samedeploystep, thanks to the use ofneedskeywords in its parameters.
Pipeline output
When a pipeline is executed, the output will look like below on the Gitlab interface (with Ansible colors).
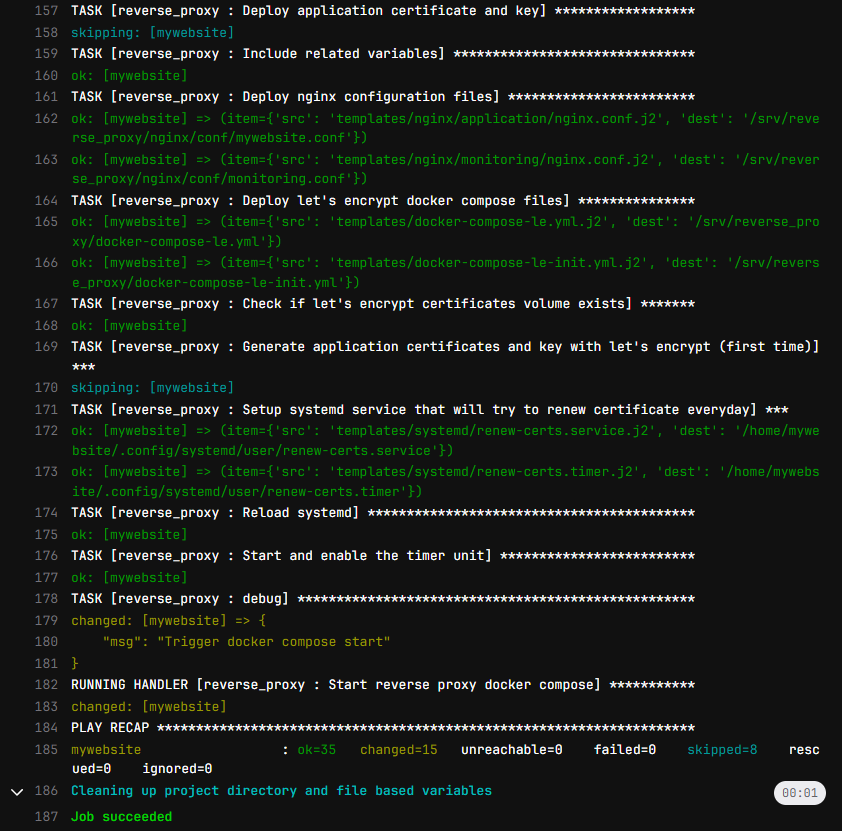
We can notice some keywords that indicate the Ansible status for each task:
ok: indicates that the task has not produced any changes on the server (e.g. copying an identical file)changed: the task has produced changes on the servers (file modification, docker compose startup, …)skipping: the task was not executed because the conditions (when) were not metfatal: task execution resulted in an error; stops the entire playbook by default, or useignore_errors : trueto bypass the error