

Introduction
Déployer une application, en particulier une application tierce, n’est généralement pas un problème majeur, et la mise à jour peut en être facilitée par le choix d’une installation conteneurisée et l’utilisation de Docker Compose par exemple. Mais s’en tenir à des tâches manuelles pour les déploiements, les mises à jour et les changements de configuration peut devenir lourd et sujet à des erreurs, en particulier si un retour en arrière est nécessaire à partir d’une configuration non versionnée.
Par ailleurs, lorsque nous n’avons à gérer qu’une poignée de conteneurs pour une application déployée sur une infrastructure simple de VMs (ce qui arrive plus souvent qu’on ne le pense :-)), il n’est pas obligatoire de pousser une configuration Kubernetes qui augmentera essentiellement les coûts de maintenance et la courbe d’apprentissage pour les nouveaux arrivants.
Ansible offre la possibilité de contrôler la configuration d’une application sur une infrastructure donnée et plusieurs environnements, et en particulier de déployer Docker Compose pour gérer le lancement des conteneurs la constituant. Gitlab est une interface de gestion de code source (SCM) qui permet de configurer la partie CI/CD (intégration continue/déploiement continu).
Nous verrons à partir du cas d’utilisation du déploiement de ce site comment faire un usage précis de ces outils afin de réaliser des déploiements à la fois sûrs et rapides.
Définition du cas d’utilisation
Dans cet article, nous allons considérer le déploiement de ce site, livré en tant que conteneur gazerad/mywebsite sur Docker hub, ainsi que d’une solution de monitoring Grafana/Prometheus/Node exporter l’accompagnant, le tout derrière un reverse proxy Nginx assurant la gestion des certificats et du trafic entrant.
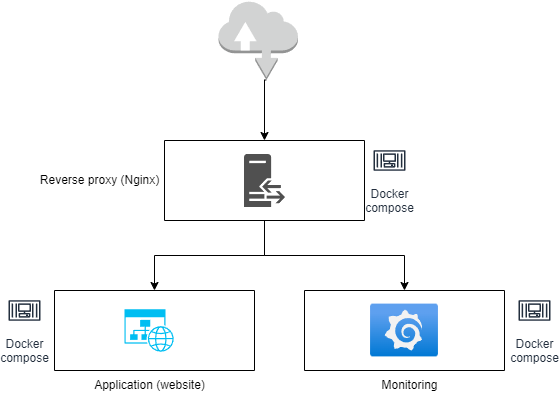
Ce déploiement doit être réalisé sur deux environnements:
- INT : un serveur déployé sur le réseau local, utilisation de certificats auto-signés.
- PROD : un serveur AWS EC2, utilisation de certificats fournis par let’s encrypt
Nous aimerions obtenir un processus d’installation où :
- La configuration est gérée as code dans un projet publié sur un SCM.
- La configuration est générée dynamiquement pour un ensemble d’environnements (ici INT et PROD)
- Les déploiements sont déclenchés par des événements push/tag sur l’outil SCM, puis lancés manuellement à partir de l’interface SCM pour l’environnement de production.
- Aucun accès utilisateur n’est requis sur l’infrastructure à déployer puisqu’aucune commande manuelle n’a besoin d’être exécutée.
C’est la situation idéale pour utiliser Ansible afin de gérer la configuration, statiquement et dynamiquement, pour la déployer sur un ensemble de serveurs/environnements. Gitlab est également un choix logique en tant qu’outil SCM qui permet également d’automatiser les tâches déclenchées par les événements SCM en définissant des pipelines.
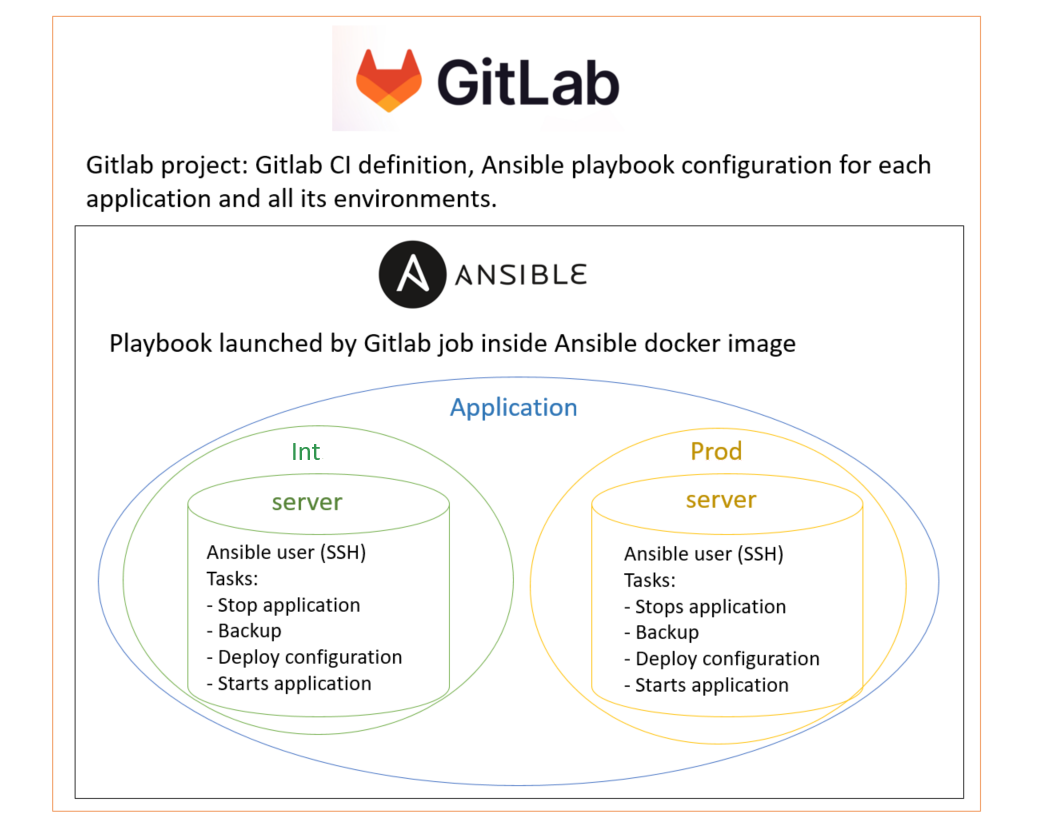
De cette manière, nous pouvons :
- nous assurer que la configuration est sauvegardée et versionnée, ce qui rend la configuration précédente immédiatement disponible et déployable en cas de retour en arrière
- limiter autant que possible l’accès des utilisateurs à l’infrastructure pour effectuer des tâches manuelles.
Par conséquent, nous pouvons améliorer la sécurité et l’efficacité des processus CI/CD en ayant la possibilité de déployer rapidement ce que nous voulons précisément.
Nous considérerons dans le reste de l’article le projet Website Core correspondant au code backend/frontend de ce site, où le deploiement Ansible est défini dans le répertoire deployments/ansible.
Nous considérons que Docker est installé sur les serveurs cibles.
Configurer Ansible et le projet Gitlab
Générer la paire de clefs SSH utilisée par Ansible
Ansible se base sur SSH pour effectuer les déploiements sur les serveurs associés à chaque environnement d’une application donnée. Par conséquent, pour chacun de ces serveurs, nous devons générer une paire de clefs SSH qui sera reconnue par l’utilisateur d’Ansible pour effectuer le déploiement.
Le serveur sur lequel se trouve la paire de clefs SSH n’a pas d’importance. Pour des raisons pratiques concernant notre cas d’utilisation, nous nommerons chaque clef comme suit : ansible_[nom de l'application]_[environnement]
Il suffit d’exécuter la commande suivante sur n’importe quel serveur pour générer la clef SSH.
ssh-keygen -t ed25519
Nous choisissons une passphrase vide car elle rend le déploiement plus difficile à automatiser s’il y en a une, et nécessite la saisie manuelle d’un mot de passe sensible.
Generating public/private ed25519 key pair.
Enter file in which to save the key (~/.ssh/id_ed25519): ~/.ssh/ansible_[application name]_[environment]
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in ~/.ssh/ansible_app_env.
Your public key has been saved in ~/.ssh/ansible_app_env.pub.
The key fingerprint is:
SHA256:/dBKUd8TExQDWoxpNTKt8xesipzAbscR9wtINJg2t9I root@SR-F1-GITRUN2
The key's randomart image is:
+--[ED25519 256]--+
| o oB=oBo|
| = + ==+..+|
| . = =.. o..|
| . E * o.|
| . S B = . .|
| o + = + . |
| . + = + o |
| o * . . |
| . . |
+----[SHA256]-----+
Maintenant, nous avons la paire de clefs SSH privée/publique disponible :
~/.ssh/ansible_[nom de l'application]_[environnement]~/.ssh/ansible_[nom de l'application]_[environnement].pub
Par exemple, pour notre cas et l’environnement d’intégration :
~/.ssh/ansible_mywebsite_int~/.ssh/ansible_mywebsite_int.pub
Convertir la paire de clefs SSH au format base64
Afin d’être ajoutées en tant que variables de projet Gitlab, nous devons convertir les clefs en une chaîne de caractères d’une ligne, nous utilisons donc l’encodage base64 pour cela.
A partir de la paire de clefs précédemment générée :
APPLICATION= # Mettez le nom de l'application ici
ENVIRONMENT= # Nom de l'environnement
# A chaque fois, nous sauvegardons la chaîne générée
cat ~/.ssh/ansible_${APPLICATION}_${ENVIRONNEMENT} | base64 -w 0
cat ~/.ssh/ansible_${APPLICATION}_${ENVIRONNEMENT}.pub | base64 -w 0
Ajouter les clefs SSH encodées aux variables du projet Gitlab
Nous allons maintenant devoir éditer les paramètres CI/CD de notre projet Gitlab afin d’ajouter les clefs encodées en tant que variables.
Notez tout d’abord que dans notre cas, les noms de variables doivent suivre la règle suivante, pour une application APPLICATION et un environnement ENVIRONMENT donnés (chacun en majuscules) :
[APPLICATION]_[ENVIRONNEMENT]_SSH_PRIVATE_KEY_BASE64
[APPLICATION]_[ENVIRONNEMENT]_SSH_PUBLIC_KEY_BASE64
Par exemple, avec l’application Mywebsite et l’environnement int :
- Clef privée :
MYWEBSITE_INT_SSH_PRIVATE_KEY_BASE64 - Clef publique :
MYWEBSITE_INT_SSH_PUBLIC_KEY_BASE64
Ensuite, nous remplissons ces variables avec les caractéristiques suivantes (décrites ici), en fonction de l’environnement :
- prod : protège et masque la variable
- int : masque uniquement la variable
Définir les mots de passe Ansible Vault comme variables Gitlab
Ansible Vault est utilisé pour crypter du contenu sensible (mots de passe, clefs privées SSH) afin de pouvoir le stocker sans risque dans des outils collaboratifs tels qu’un SCM (dans notre cas, le projet Gitlab).
Pour ce faire, nous avons besoin d’un mot de passe maître qui permettra de décrypter le contenu “vaulté”. Dans notre cas, comme nous disposons de deux environnements, nous allons choisir deux mots de passe Vault afin de crypter les variables sensibles de chacun des deux environnements. Logiquement, ceux-ci ne pourront pas être publiés directement dans le projet Gitlab.
Nous n’avons pas véritablement besoin de jongler entre ces mots de passe Vault puisque leur utilisation se limitera aux pipelines CI/CD Gitlab, donc il ne sera pas nécessaire de se servir de la fonctionnalité de Vault IDs.
Nous allons donc définir deux mots de passe Vault qui seront stockés en tant que variables Gitlab du projet :
- prod :
ANSIBLE_VAULT_PASSWORD_PROD - int :
ANSIBLE_VAULT_PASSWORD_INT
De la même façon que précédemment, ces variables auront les caractéristiques suivantes :
- prod : protège et masque la variable
- int : masque uniquement la variable
Crypter les mots de passe avec Ansible Vault
A l’aide des mots de passe Vault que nous venons de générer, nous allons pouvoir maintenant crypter les données sensibles de notre application.
Celles-ci pourront alors être ajoutées, une fois chiffrées, dans le fichier vault.yml de l’inventaire correspondant à l’environnement considéré.
Pour crypter un mot de passe, il faut procéder ainsi, en se munissant du mot de passe Vault de l’environnement (INT ou PROD).
# Ouvrez le fichier .vault_pass et mettez-y le mot de passe vault
vi .vault_pass
# Définir la variable d'environnement ANSIBLE_VAULT_PASSWORD_FILE
export ANSIBLE_VAULT_PASSWORD_FILE=./.vault_pass
# Cryptage du mot de passe
ansible-vault encrypt_string 'mon_mot_de_passe'
Nous obtenons alors le mot de passe chiffré :
Encryption successful
!vault |
$ANSIBLE_VAULT;1.1;AES256
30386565656261343265343138663433643837366132616566653239396635323565643931373035
3261386338353031323633663835313332346466386162660a383761393130633562633132313839
64613162373531643064646233613062316336616632356162623536386437396538306136616136
3035396131353636350a376338353461643136363135613762623039623031313562623365336265
30656464316461313638326636646563306464663962626432316631626130353765316231626566
6463306337623163306339303438653163366331343439626534
Configurer l’utilisateur ansible sur les serveurs cibles
Ansible a besoin d’un utilisateur disposant des caractéristiques suivantes sur les serveurs cibles :
- droits sudo
- sans mot de passe : sinon, l’automatisation devient difficile à gérer sans plus-value sécuritaire indispensable
- sur toutes les commandes : limiter le périmètre des commandes sudo est découragé par la documentation officielle puisqu’Ansible encapsule les commandes avec Python et en exécute beaucoup d’autres que celles définies dans le playbook.
- pas de mot de passe utilisateur : pour des raisons de sécurité, seule l’authentification par clef SSH est autorisée.
Il faut donc exécuter les commandes suivantes avec un utilisateur disposant lui aussi de droits sudo suffisants :
# Créer l'utilisateur ansible avec des droits sudo sur toutes les commandes
sudo useradd -m ansible -s /bin/bash
sudo usermod -aG sudo ansible
echo "ansible ALL=(ALL) NOPASSWD:ALL" | sudo tee /etc/sudoers.d/ansible
# Supprimer l'authentification par mot de passe
sudo passwd -l ansible
Maintenant, nous allons ajouter la clef publique précédemment générée à la configuration de l’utilisateur ansible que nous venons de créer.
Pour ce faire, il faut exécuter les commandes suivantes en se connectant avec l’utilisateur ansible :
# Exécuter avec l'utilisateur ansible
mkdir -p ~/.ssh
echo "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" | tee -a ~/.ssh/authorized_keys
Selon le playbook devant être exécuté, il faudra éventuellement installer des bibliothèques supplémentaires avec pip.
Définition du playbook de déploiement Ansible
L’objectif du playbook sera d’effectuer le déploiement du site et de la solution de monitoring derrière un reverse proxy Nginx.
Organisation du contenu du playbook
Conformément aux bonnes pratiques d’Ansible, nous avons défini comme suit le contenu du playbook de déploiement dans le répertoire deployments/ansible du projet Gitlab.
├── inventories
│ ├── 000_cross_env_vars.yml
│ ├── 001_versions.yml
│ ├── int
│ │ ├── group_vars
│ │ │ └── all
│ │ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ │ ├── vars.yml
│ │ │ └── vault.yml
│ │ └── hosts
│ └── prod
│ ├── group_vars
│ │ └── all
│ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ ├── vars.yml
│ │ └── vault.yml
│ └── hosts
├── roles
│ ├── application
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── monitoring
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── reverse_proxy
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ └── server
│ ├── defaults
│ ├── files
│ ├── handlers
│ ├── meta
│ ├── tasks
│ ├── templates
│ └── vars
├── playbook-deploy.yml
└── playbook-setup.yml
Nous pouvons remarquer 3 catégories principales que nous détaillerons par la suite :
- les inventaires : sous le répertoire
inventories, définissent le contenu des environnementsintetproddans notre cas, tel que la liste des serveurs cibles (hosts), des variables communes ou spécifiques à chaque inventaire etc. - les rôles : sous le répertoire
rolessont regroupés par élément logique de la configuration (application, serveur, reverse proxy, …) tout ce qui permettra d’exécuter les tâches en rapport dans un playbook, donc aussi bien les fichiers/templates amenés à être déployés que la définition des tâches, des variables spécifiques… - les playbooks : situés à la racine du répertoire, ce sont des fichiers qui regroupent les tâches/rôles à exécuter selon le cas souhaité.
Inventaires : configuration générale des variables
├── inventories
│ ├── 000_cross_env_vars.yml
│ ├── 001_versions.yml
│ ├── int
│ │ ├── group_vars
│ │ │ └── all
│ │ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ │ ├── vars.yml
│ │ │ └── vault.yml
│ │ └── hosts
│ └── prod
│ ├── group_vars
│ │ └── all
│ │ ├── 000_cross_env_vars.yml -> ../../../000_cross_env_vars.yml
│ │ ├── 001_versions.yml -> ../../../001_versions.yml
│ │ ├── vars.yml
│ │ └── vault.yml
│ └── hosts
Afin que le code du playbook puisse fonctionner sur différents ensembles hosts/variables en fonction de l’environnement choisi, nous devons définir un inventaire.
L’inventaire est défini par un ensemble de dossiers/sous-dossiers dans le dossier inventories.
Configuration de l’environnement
Les deux environnements, int et prod, ont la même structure arborescente qui suit les pratiques suggérées.
group_vars/all : contient la définition des variables requises par l’environnement. Le nom du dossier
all/indique que ces variables s’appliquent à chaque groupe de hosts défini dans le fichierhostsque nous détaillerons plus loin. Ici, nous pouvons voir que nous avons le contenu suivant :- vars.yml : contient les variables spécifiques à l’environnement.
# Websites fqdn mywebsite_fqdn: gazerad.com mywebsite_fr_fqdn: gazerad.fr grafana_fqdn: grafana.mywebsite.com prometheus_fqdn: prometheus.mywebsite.com # Certificates configuration monitoring_cert_name: monitoring # let's encrypt variables lets_encrypt_use: true mywebsite_email: guillaume.azerad@gap-cs.com- vault.yml : contient des variables “vaultées”, qui sont des mots de passe chiffrés avec Ansible vault. Les données peuvent être ainsi publiées sur Gitlab car elles sont effectivement cryptées.
vault_mywebsite_password: !vault | $ANSIBLE_VAULT;1.1;AES256 30386565656261343265343138663433643837366132616566653239396635323565643931373035 3261386338353031323633663835313332346466386162660a383761393130633562633132313839 64613162373531643064646233613062316336616632356162623536386437396538306136616136 3035396131353636350a376338353461643136363135613762623039623031313562623365336265 30656464316461313638326636646563306464663962626432316631626130353765316231626566 6463306337623163306339303438653163366331343439626534- liens symboliques : ils renvoient à des fichiers contenant des variables qui ont les mêmes valeurs dans tous les environnements.
hosts : ce fichier contient la définition des serveurs (hosts) pour l’application et l’environnement sélectionnés. Il faut d’abord indiquer le nom du groupe de serveurs (
[application]ici), puis on liste sur la même ligne :- le nom du serveur utilisé par les tâches des playbooks (ici
mywebsite_debianetmywebsite_ubuntu) - le FQDN ou l’adresse IP du host distant (variable
ansible_host) - l’utilisateur qu’Ansible utilisera pour se connecter au serveur et exécuter le playbook (variable
ansible_user)
- le nom du serveur utilisé par les tâches des playbooks (ici
Nous pouvons aussi définir beaucoup d’autres variables telles que
ansible_portqui permet d’attribuer un port ssh alternatif qu’Ansible va devoir utiliser pour se connecter au serveur.
Comme indiqué précédemment, l’environnement d’intégration dispose de deux serveurs identifiés par leur nom au début de leur définition.
[application]
mywebsite_debian ansible_host=gazerad-int.com ansible_user=ansible
mywebsite_ubuntu ansible_host=gazerad-int2.com ansible_user=ansible
Nous avons choisi ici le format
.inipour ce fichier mais il aurait pu être écrit en YAML, Ansible accepte les deux formats pour définir la configuration du playbook.
Configuration globale
Nous avons également deux fichiers qui contiennent des définitions de variables identiques pour tous les environnements. Comme expliqué précédemment, ils sont répliqués dans chaque configuration d’environnement par un lien symbolique.
- 000_cross_env_vars.yml : contient simplement des définitions de variables qui s’appliquent à tous les environnements. Idéalement, il faut se limiter à des données générales définissant des valeurs précises (FQDN, URL, nom d’user, …). Les autres variables plus spécifiques à chaque élément de configuration doivent être définies dans les rôles correspondants.
IMPORTANT : il y a une section qui applique les variables “vaultées” à un autre nom de variable. Ceci a été fait pour éviter de remplir ce fichier avec des mots de passe “vaultés”, ce qui l’aurait rendu difficile à lire.
# Passwords and keys
mywebsite_password: "{{ vault_mywebsite_password }}"
grafana_admin_password: "{{ vault_grafana_admin_password }}"
external_website_data_access_token: "{{ vault_external_projet_access_token }}"
# gitlab.com website-data project configuration
external_gitlab_api_v4_url: "https://gitlab.com/api/v4"
external_website_data_id: 55398930
# General paths on the server
application_dir: /srv/web
reverse_proxy_dir: /srv/reverse_proxy
monitoring_dir: /srv/monitoring
# Usernames for applications
grafana_user: gazerad
- 001_versions.yml : contient essentiellement les versions des services définis dans les fichiers docker compose. C’est ce fichier qui doit être modifié pour une mise à jour de version des services. Il contient aussi les versions de packages devant être installés sur les serveurs (ici:
docker: 26.0.0)
versions:
docker: 26.0.0
nginx: 1.25.4
certbot: v2.10.0
autoheal: 1.2.0
grafana: 10.4.1
prometheus: v2.51.0
node_exporter: v1.7.0
Définition des rôles
├── roles
│ ├── application
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── monitoring
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ ├── reverse_proxy
│ │ ├── defaults
│ │ ├── files
│ │ ├── handlers
│ │ ├── meta
│ │ ├── tasks
│ │ ├── templates
│ │ └── vars
│ └── server
│ ├── defaults
│ ├── files
│ ├── handlers
│ ├── meta
│ ├── tasks
│ ├── templates
│ └── vars
Comme expliqué précédemment, chaque rôle correspond à un élément de la configuration déployée par le playbook playbook-deploy.yml.
- application : le site web conteneurisé
- monitoring : la solution de monitoring Grafana-Prometheus-Node exporter
- reverse_proxy : le reverse proxy Nginx gérant les certificats et routant le trafic entrant vers le endpoint souhaité
Dans chaque cas, nous allons déployer un fichier Docker Compose contenant la définition des services de chaque rôle, et qui sera inclus dans celui du rôle reverse_proxy qui fera donc tourner en tâche de fond l’ensemble des services constituant l’application déployée.
Le rôle server est utilisé par le playbook playbook-setup.yml s’occupant de la configuration des serveurs cibles (installation de paquets Debian, de Docker, …) que nous ne détaillerons pas dans ce document.
Puisque tous les rôles ont la même structure, nous allons nous focaliser sur le rôle reverse_proxy pour en décrire le contenu.
├── reverse_proxy
│ ├── defaults
│ │ └── main.yml
│ ├── files
│ │ └── certs
│ │ ├── application
│ │ │ ├── gazerad.crt
│ │ │ ├── gazerad-int.crt
│ │ │ ├── gazerad-int.key.vault
│ │ │ └── gazerad.key.vault
│ │ └── monitoring
│ │ ├── monitoring.crt
│ │ ├── monitoring-int.crt
│ │ ├── monitoring-int.key.vault
│ │ └── monitoring.key.vault
│ ├── handlers
│ │ └── main.yml
│ ├── meta
│ │ └── main.yml
│ ├── tasks
│ │ ├── common_certs.yml
│ │ ├── le_certs.yml
│ │ └── main.yml
│ ├── templates
│ │ ├── docker-compose-le-init.yml.j2
│ │ ├── docker-compose-le.yml.j2
│ │ ├── docker-compose.yml.j2
│ │ ├── nginx
│ │ │ ├── application.conf.j2
│ │ │ └── monitoring.conf.j2
│ │ └── systemd
│ │ ├── renew-certs.service.j2
│ │ └── renew-certs.timer.j2
│ └── vars
│ ├── common_certs.yml
│ └── le_certs.yml
- defaults : ce répertoire rassemble les définition de valeurs par défaut pour les variables spécifiques au rôle. Son contenu est automatiquement lu par Ansible lorsqu’on exécute un playbook, il n’y a donc pas besoin d’inclure spécifiquement les fichiers le composant. Nous pouvons remarquer l’utilisation de la structure Jinja2
{{ varname }}pour récupérer la valeur d’une variable précédemment définie.
# Nginx configuration
nginx_dir: "{{ reverse_proxy_dir }}/nginx"
nginx_conf_dir: "{{ reverse_proxy_dir }}/nginx/conf"
nginx_mywebsite_path: "{{ nginx_conf_dir }}/mywebsite.conf"
nginx_monitoring_path: "{{ nginx_conf_dir }}/monitoring.conf"
files : ce répertoire contient les fichiers (de configuration ou autres) qui seront déployés tels quels, sans modification, par le playbook.
handlers : nous avons ici les handlers permettant de déclencher des événements après qu’une tâche soit passé au status
changed. Par défaut, les handlers sont exécutés à la fin du playbook mais il est possible de forcer leur lancement juste après une tâche. Il est généralement pertinent de définir des évènements d’arrêt-relance de services, pouvant aussi être appelés par d’autres rôles en cas de dépendance.
- name: Stop docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: absent
become_user: mywebsite
- name: Start docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: present
become_user: mywebsite
- name: Restart docker compose
docker_compose_v2:
project_src: "{{ reverse_proxy_dir }}"
docker_host: "{{ docker_host }}"
state: restarted
become_user: mywebsite
- meta : cette section est dédiée aux métadonnées du rôle. Il est surtout utile de la remplir lorsque nous souhaitons publier le rôle sur Ansible Galaxy. Dans notre cas, nous nous limiterons à indiquer les dépendances avec des modules Ansible Galaxy.
collections:
- ansible.builtin
- community.docker
- community.general
tasks : ce répertoire contient la définition des tâches qui seront exécutées par le playbook dans lequel le rôle est importé. Le fichier main.yml est automatiquement lu lorsqu’on importe le rôle; nous voyons aussi deux fichiers common_certs.yml et le_certs.yml qui, eux, sont directement mentionnés dans le main.yml avec la directive
import_tasks.templates : nous avons ici des fichiers déployés sur les serveurs cibles, mais contrairement aux répertoire files ils contiennent des parties variabilisées sous forme Jinja2
{{ varname }}qui seront renseignées lors de l’exécution des tâches. Par exemple ci-dessous, pour le fichier Docker Compose :
# {{ ansible_managed | comment }}
include:
- {{ application_dir }}/docker-compose.yml
- {{ monitoring_dir }}/docker-compose.yml
services:
reverse_proxy:
image: nginx:{{ versions.nginx }}
container_name: reverse_proxy
restart: always
networks:
- frontend
- monitoring
ports:
- 80:80
- 443:443
volumes:
- "{{ nginx_mywebsite_path }}:/etc/nginx/conf.d/mywebsite.conf:ro"
- "{{ nginx_monitoring_path }}:/etc/nginx/conf.d/monitoring.conf:ro"
- "{{ nginx_certs_dir }}:{{ nginx_container_certs_dir }}:ro"
- "{{ nginx_log_dir }}:/var/log/nginx"
- /etc/localtime:/etc/localtime:ro
{% if lets_encrypt_use %}
# Manage certificates generated by let's encrypt
- certs:/etc/letsencrypt
{% endif %}
# DEPRECATED : import CA certificates from the server into the nginx container
# - /etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt:ro
healthcheck:
test: ["CMD", "curl", "-f", "localhost"]
interval: 30s
timeout: 10s
retries: 3
labels:
autoheal: true
networks:
frontend:
monitoring:
{% if lets_encrypt_use %}
volumes:
certs:
name: letsencrypt
external: true
{% endif %}
- vars : cette section rassemble des définitions de variables plus spécifiques que dans la partie defaults et pouvant éventuellement les surcharger. Dans notre cas, nous avons eu besoin de définir conditionnellement des variables (qui dépendant en l’occurence de la valeur d’une variable définie dans l’inventaire) donc nous avons créé deux fichiers qui seront inclus de la sorte dans les tâches :
- name: Include related variables
include_vars:
file: le_certs.yml
Définition du playbook
├── playbook-deploy.yml
Enfin, le playbook playbook-deploy.yml orchestre les rôles précédemment définis afin d’exécuter le déploiement de l’application sur l’inventaire sélectionné.
Dans notre cas, nous avons défini un seul playbook exécutant les rôles à la suite, ce qui fait que les handlers déclenchés dans chaque rôle ne sont exécutés qu’à la fin du playbook complet.
- name: Applicative deployment playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: application
tags:
- application
- role: monitoring
tags:
- monitoring
- role: reverse_proxy
tags:
- application
- monitoring
- reverse_proxy
Si nous avions souhaité déclencher les handlers à la fin des tâches de chaque rôle, nous aurions dû définir trois “sous-playbooks” correspondant à chacun d’entre eux.
- name: Deploy application playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: application
tags:
- application
- name: Deploy monitoring playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: monitoring
tags:
- monitoring
- name: Deploy reverse proxy playbook
hosts: mywebsite
become: true
gather_facts: true
roles:
- role: reverse_proxy
tags:
- application
- monitoring
- reverse_proxy
Remarquons quelques points :
tags: les rôles se voient attribuer une liste de tags, cela permet d’exécuter le playbook pour uniquement certaines tâches et non en totalité. Par exemple, si je ne veux déployer que l’application en intégration, j’ajoute le tagapplicationà la commande d’exécution du playbook qui déroulera les rôlesapplicationetreverse_proxy.
ansible-playbook -i inventories/int --tags application playbook-deploy.yml
hosts: nous faisons ici référence au fichier hosts de l’inventaire en donnant le nom de la liste de serveurs sur lequel le playbook sera exécuté.become: true: il s’agit ici d’indiquer que l’useransiblequi exécutera le playbook sur les serveurs cibles bénéficiera de droitssudo, ce qui sera entre autre utile pour “devenir” un autre user sur le serveur (dans notre cas l’usermywebsite).gather_facts: true: c’est la valeur par défaut pour déterminer si le playbook récupère les facts. Nous avons indiqué la directive afin de la passer aisément àfalsesi nous estimons ne plus avoir besoin des facts.
Pipeline de déploiement Gitlab CI
Nous allons maintenant décrire l’utilisation de Gitlab CI et de ses pipelines déclenchées automatiquement pour procéder au déploiement de notre application par l’intermédiaire du playbook Ansible précédemment décrit.
Flux d’exécution du pipeline
Le projet Gitlab Website Core dispose d’un pipeline CI/CD réalisant le build de l’application ainsi que la publication de l’image Docker sur Docker Hub.
Nous allons simplement ajouter une étape deploy à la fin du pipeline afin d’assurer le déploiement sur les environnements d’intégration et de production, en suivant ces lignes directrices:
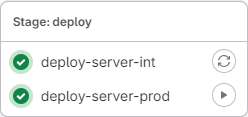
- Un job sera défini dans l’étape
deploypour chaque environnement :deploy-server-intetdeploy-server-prod. - Le job
deploy-server-intsera exécuté automatiquement alors quedeploy-server-prodsera lancé manuellement. deploy-server-proddépend de la bonne exécution dedeploy-server-int. En cas d’erreur, son lancement sera bloqué.- Les évènements déclencheurs qui ajouteront ces jobs dans le pipeline sont :
deploy-server-int: un tag de release candidate (X.X.X-rcXoù X est un entier natuel) ou un tag de release (X.X.X)deploy-server-prod: un tag de release (X.X.X), et l’exécution sera manuelle.
Lorsque les conditions sont réunies pour ajouter le déploiement au pipeline, l’étape deploy sera affichée ainsi dans le menu des pipelines Gitlab :
Code Gitlab CI
Le fichier .gitlab-ci.yml du projet Website Core applique le flux d’exécution précédent lors de l’étape deploy.
Nous allons détailler ci-dessous le contenu des jobs de déploiement qui exécutent le playbook Ansible.
variables:
...
ANSIBLE_VERSION: !reference [ .dependencies, images, ansible ]
stages:
...
- deploy
.rules:
# Manages CI/CD process for release and release candidate tagging events
tag_release:
- if: $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+$/ && $DEPLOY_MODE != "Y"
variables:
RELEASE_TYPE: "release"
tag_release_candidate:
- if: $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+-rc\d+$/ && $DEPLOY_MODE != "Y"
variables:
RELEASE_TYPE: "release_candidate"
# Only deploy an existing tagged package from web pipelines
deploy_release:
- if: $CI_PIPELINE_SOURCE == "web" && $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+$/ && $DEPLOY_MODE == "Y"
variables:
RELEASE_TYPE: "release"
deploy_release_candidate:
- if: $CI_PIPELINE_SOURCE == "web" && $CI_COMMIT_TAG =~ /^\d+\.\d+\.\d+-rc\d+$/ && $DEPLOY_MODE == "Y"
variables:
RELEASE_TYPE: "release_candidate"
...
...
# Job to manage the deployment of the application to a Linux server with Ansible
deploy-server-int:
stage: deploy
image: ${CI_DEPENDENCY_PROXY_GROUP_IMAGE_PREFIX}/cytopia/ansible:$ANSIBLE_VERSION
rules:
- !reference [.rules, tag_release_candidate]
- !reference [.rules, tag_release]
- !reference [.rules, deploy_release_candidate]
- !reference [.rules, deploy_release]
variables:
ANSIBLE_FORCE_COLOR: 'true' # get Ansible colors displayed on Gitlab UI
APP_NAME: mywebsite
ENV: int
MYWEBSITE_VERSION: $CI_COMMIT_TAG
before_script:
# To resolve potential timeouts on my home network
- echo -e "\nnameserver 1.1.1.1" >> /etc/resolv.conf
script:
- echo "INFO - Application to be deployed is $APP_NAME"
- if [ "X$ENV" == "X" ]; then ENV=$(echo "$CI_JOB_NAME" | awk -F "_|-" '{print $NF}'); fi
- echo "INFO - Environment is $ENV"
# We expect SSH key variables to match the following name : ${APP_NAME}_${ENV}_SSH_(PRIVATE|PUBLIC)_KEY_BASE64
- SSH_PRIVATE_KEY_BASE64_VARNAME=$(echo "${APP_NAME}_${ENV}_SSH_PRIVATE_KEY_BASE64" | tr '[:lower:]' '[:upper:]')
- eval "SSH_PRIVATE_KEY_BASE64=\${$SSH_PRIVATE_KEY_BASE64_VARNAME}"
- SSH_PUBLIC_KEY_BASE64_VARNAME=$(echo "${APP_NAME}_${ENV}_SSH_PUBLIC_KEY_BASE64" | tr '[:lower:]' '[:upper:]')
- eval "SSH_PUBLIC_KEY_BASE64=\${$SSH_PUBLIC_KEY_BASE64_VARNAME}"
# Test if required variables are filled
- |-
if [ "X$APP_NAME" == "X" ] || [ "X$ENV" == "X" ] || [ "X$SSH_PRIVATE_KEY_BASE64" == "X" ] || [ "X$SSH_PUBLIC_KEY_BASE64" == "X" ]
then
echo "ERROR - One of the required variable was missing. Please check your configuration."
exit 1
fi
# Setup SSH key pair that will be used to authenticate against target server
- echo "INFO - Adding SSH key pair provided by Gitlab project variables to local SSH configuration"
- mkdir -p ~/.ssh
- echo "$SSH_PRIVATE_KEY_BASE64" | base64 -d > ~/.ssh/id_ed25519
- chmod 600 ~/.ssh/id_ed25519
- echo "$SSH_PUBLIC_KEY_BASE64" | base64 -d > ~/.ssh/id_ed25519.pub
# Add target host fingerprint to local known_hosts
# We consider here potentially multiple hosts related to the application (not the current use case though)
- APPLICATION_SERVER_FQDN_LIST=$(grep $APP_NAME deployments/ansible/inventories/${ENV}/hosts | awk 'BEGIN{RS=" "; FS="ansible_host="}NF>1{print $NF}')
- echo "INFO - Adding host fingerprints to local known_host for $APP_NAME application servers FQDN list ($ENV environment) - $(echo $APPLICATION_SERVER_FQDN_LIST)"
- |-
for APPLICATION_SERVER_FQDN in $APPLICATION_SERVER_FQDN_LIST; do
# If we are in integration, we edit /etc/hosts to add the IP address of the target server
if [ "$ENV" == "int" ]; then
IP_ADDR_VARNAME=$(echo "${APP_NAME}_${ENV}_IP_ADDR" | tr '[:lower:]' '[:upper:]')
eval "IP_ADDR=\${$IP_ADDR_VARNAME}"
echo -e "\n$IP_ADDR $APPLICATION_SERVER_FQDN" >> /etc/hosts
fi
ssh-keyscan -H $APPLICATION_SERVER_FQDN >> ~/.ssh/known_hosts
done
# Go to ansible deployments folder
- cd $CI_PROJECT_DIR/deployments/ansible
# Setup Ansible vault configuration
- echo "INFO - Setting up Ansible vault configuration"
- ANSIBLE_VAULT_PASSWORD_VARNAME=$(echo "ANSIBLE_VAULT_PASSWORD_${ENV}" | tr '[:lower:]' '[:upper:]')
- eval "ANSIBLE_VAULT_PASSWORD=\${$ANSIBLE_VAULT_PASSWORD_VARNAME}"
- echo "$ANSIBLE_VAULT_PASSWORD" > .vault_pass
- export ANSIBLE_VAULT_PASSWORD_FILE=./.vault_pass
# Launch the Ansible playbook
- ansible-playbook -i inventories/$ENV playbook-deploy.yml
# Deployment to prod server
deploy-server-prod:
extends: deploy-server-int
rules:
- !reference [.rules, tag_release]
- !reference [.rules, deploy_release]
variables:
ENV: prod
when: manual
needs: [ "deploy-server-int" ]
En résumé, les étapes du job de déploiement sont les suivantes :
- Récupération des clefs SSH à partir des variables de projet Gitlab et en fonction du couple application/environnement (
mywebsite/intoumywebsite/prodici) - Modification en conséquence de la configuration ssh du conteneur dans lequel le job est exécuté pour pouvoir directement utiliser les clefs.
- Ajout de l’empreinte digitale du/des serveurs sur lesquels on effectue le déploiement. C’est une étape essentielle afin qu’aucune confirmation ne soit demandée lors de l’exécution du playbook.
- Installation de la configuration Ansible Vault : il s’agit ici de récupérer à partir des variables de projet Gitlab le mot de passe Vault corresponant à l’environnement donné, et de l’écrire dans un fichier
.vault_passà l’endroit où se situe le playbook. - Exécution du playbook
playbook-deploy.ymlavec l’inventaire de l’environnement donné
Nous pouvons aussi remarquer que :
- Les jobs sont exécutés dans un conteneur créé à partir de l’image cytopia/ansible qui propose une version conteneurisée d’Ansible
- La variable
ANSIBLE_FORCE_COLOR: 'true'sert à afficher les couleurs “Ansible” dans la log d’exécution du job - Le job
deploy-server-prodne consiste qu’en une extension du jobdeploy-server-intavec la redéfinition de quelques variables. - Ce même job
deploy-server-proddépend du jobdeploy-server-intbien qu’appartenant à la même étapedeploygrâce à l’utilisation de mot-clefsneedsdans ses paramètres.
Sortie du pipeline
Lorsqu’on exécute un pipeline, la sortie sera comme ci-dessous sur l’interface Gitlab (avec les couleurs Ansible).
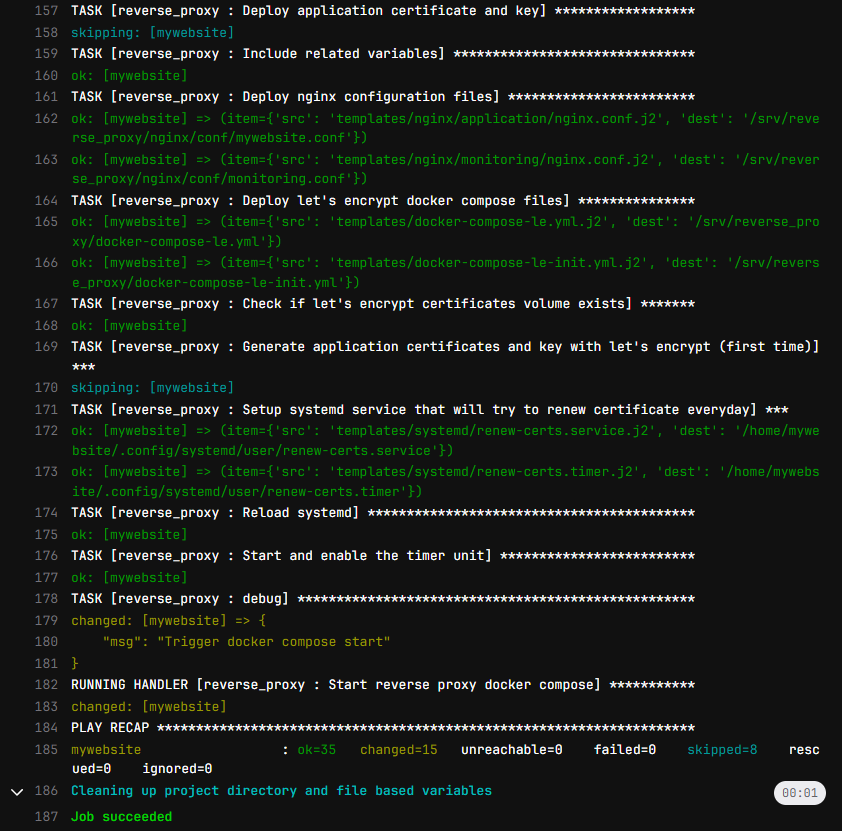
Nous pouvons remarquer quelques mots-clefs qui indiquent le statut d’Ansible pour chaque tâche :
ok: indique que la tâche n’a produit aucun changement sur le serveur (par exemple copie d’un fichier identique)changed: la tâche a produit des changements sur les serveurs (modification d’un fichier, démarrage de docker compose, …)skipping: la tâche n’a pas été exécutée car les conditions (when) n’étaient pas rempliesfatal: l’exécution de la tâche a résulté en une erreur ; arrête tout le playbook par défaut, ou l’utilisation deignore_errors : truepermet de contourner l’erreur