

Introduction
Ca y est ! Nous sommes au début d’un projet et nous venons de parvenir à développer un programme qui fonctionne et répond aux exigences. Parfait donc, il n’y a plus qu’à livrer en production…
Oui mais… des questions se posent immédiatement :
Compatibilité environnementale : est-ce que le programme fonctionne de la même manière dans différents environnements ? Par exemple, il pourrait marcher sur en développement, mais qu’en est-il du serveur de production ? Des différences dans les configurations, les versions des dépendances ou même le système d’exploitation peuvent provoquer des dysfonctionnements imprévus.
Gestion des dépendances : comment allons-nous gérer les dépendances du programme ? Si le programme dépend de bibliothèques spécifiques, comment s’assurer que ces bibliothèques seront disponibles et compatibles sur le serveur de production ?
Portabilité : comment s’assurer que notre application est facilement déployable sur différentes infrastructures, que ce soit en local, sur des serveurs sur site ou dans le cloud ?
Isolation : comment garantir que notre programme ne causera pas de conflits avec d’autres applications ou services sur le même serveur ? L’isolation des environnements de runtime est cruciale pour éviter des problèmes d’interférence.
Scalabilité : notre programme est-il prêt à être mis à l’échelle ? Si nous avons besoin de plus de puissance ou si nous devons gérer une augmentation du nombre d’utilisateurs, comment allons-nous adapter notre déploiement ?
Maintenance et mises à jour : comment allons-nous gérer les mises à jour du programme ? Est-il possible de mettre à jour ou de corriger notre application sans provoquer d’interruptions de service ?
Sécurité : quelles sont les implications de sécurité lors du déploiement de notre application ? Comment allons-nous protéger notre application contre les vulnérabilités, les accès non autorisés et autres menaces ?
Pour répondre à ces questions et faciliter le déploiement de notre application, une solution efficace est la conteneurisation.
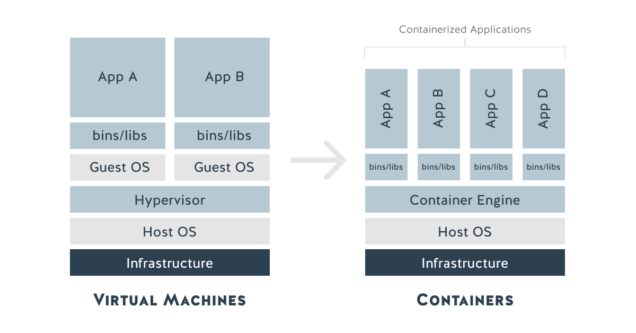
La conteneurisation est une méthode qui permet d’encapsuler une application et toutes ses dépendances dans un conteneur léger, portable et autosuffisant. Cette approche offre plusieurs avantages :
- Uniformité : les conteneurs permettent de garantir que le programme fonctionne de la même manière, quel que soit l’environnement, en encapsulant toutes les dépendances nécessaires.
- Isolation : chaque conteneur est isolé des autres, ce qui évite les conflits de dépendances et les interférences entre applications.
- Portabilité : les conteneurs peuvent être déployés facilement sur différentes plateformes, que ce soit sur des machines locales, des serveurs sur site ou dans le cloud.
- Scalabilité : les conteneurs peuvent être répliqués et orchestrés facilement pour répondre à des besoins de scalabilité.
En adoptant la conteneurisation, nous pouvons rendre notre application plus robuste, flexible et facile à gérer. Dans les sections suivantes, nous allons partir du cas d’étude de ce site web livré sous forme conteneurisée et proposer un processus de build automatisé dans Gitlab CI.
Cas d’utilisation
Nous allons considérer le cas de ce site qui consiste en :
- un exécutable compilé en langage Go (back-end)
- des fichiers statiques (pages HTML, scripts, CSS, médias) et dynamiques (templates HTML) diffusés par le serveur web
- une base de données Sqlite contenant la définition des articles et des tags
En raison de leur cycle de vie différent, nous avons choisi de séparer le site web à proprement parler des articles en deux projets Gitlab différents : Website Core pour le moteur du site et Website Data pour la gestion des articles ainsi que la base de données Sqlite.
Le site web ne servant que le protocole HTTP (pour conserver la simplicité du code), il sera amené à tourner derrière un proxy inversé qui gèrera la partie SSL avec les certificats.
Nous percevons ainsi tout l’intérêt de la conteneurisation qui permet au proxy inversé et au site de communiquer dans un réseau étanche n’exposant que le port 443 dédié aux communications https vers l’extérieur.
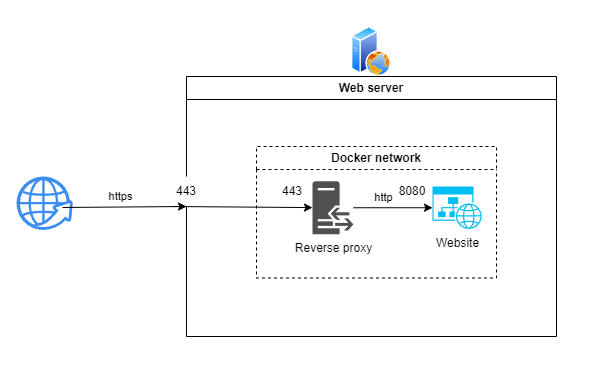
Il est de plus évident que les différents services de l’application dans son ensemble (ici le proxy inversé et le site web) disposeront chacun de leur environnement en toute autonomie, sans conflit de dépendances.
Le défi de la conteneurisation que nous allons détailler consiste donc à :
- générer une image Docker sécurisée et la plus économe possible pour le site web
- intégrer la génération de cette image et le déploiement du conteneur au processus CI/CD (ici avec Gitlab)
Conteneuriser l’application avec Docker
Nous considérons comme pré-requis l’installation de Docker Engine ou de Docker Desktop sur l’environnement où l’on développe le site web.
Il existe des alternatives à Docker comme système d’exécution de conteneurs : Podman, LXC, rkt, CRI-O, containerd qui peuvent présenter des caractéristiques plus adaptées à l’application que l’on souhaite conteneuriser.
Analyser le code et ses dépendances
La première question à se poser est : de quoi mon application a-t-elle absolument besoin pour tourner ?
Le projet Website Core consiste en un back-end développé en langage Go et des fichiers statiques ou dynamiques (i.e. au contenu édité par le programme Go). Le site web généré par le précédent projet devra servir des articles sous forme de pages HTML et une base de données Sqlite composée d’un fichier provenant du projet Website Data.
Nous pouvons déjà remarquer que :
- le langage Go est un langage compilé : il n’y a nul besoin de déployer le code mais simplement l’exécutable généré par la compilation.
- pas besoin non plus des dépendances ayant permis cette compilation : il faut juste s’assurer que l’OS ayant été utilisé pour celle-ci et celui du conteneur dans lequel tournera l’application sont identiques.
- pour fonctionner, l’application n’a besoin que des fichiers statiques/dynamiques du projet Website Core. Les articles et la base de données peuvent lui être associés plus tard.
Déterminer les données persistantes
Comme nous venons de l’aborder, il faut opérer une distinction entre ce qui constitue le coeur de l’application assurant son fonctionnement essentiel qui constituera le conteneur lui-même, et les données devant être conservées et/ou modifiées de l’extérieur (configuration, base ou fichiers de données).
La documentation officielle explique que le système de stockage Docker repose sur :
- des couches (layers) en écriture seule et persistantes qui contiennent l’image
- une couche en lecture-écriture pour chaque conteneur en cours d’exécution
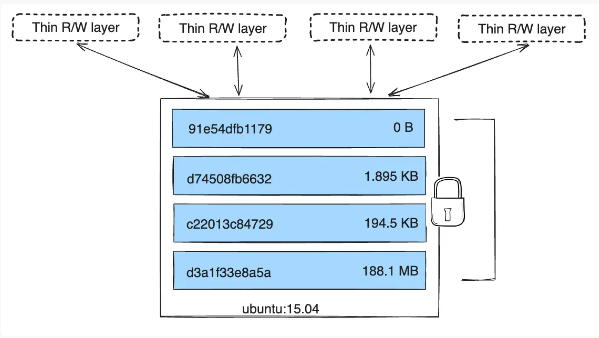
De la sorte, toutes les données modifiées dans un conteneur le sont dans la couche en lecture-écriture éphémère qui est donc supprimée lorsque le conteneur est arrêté.
Heureusement, Docker propose la notion de volume qui permet de monter des répertoires/fichiers partagés entre le conteneur et son hôte afin de conserver des données persistantes ou modifiables de l’extérieur. Ceci a aussi l’avantage de limiter la taille de l’image Docker en ne conservant que le nécessaire permettant d’exécuter le conteneur correspondant.
L’utilisation du terme volume est un abus de langage qui regroupe des éléments différents adaptés à tel ou tel cas d’utilisation: les volumes eux-mêmes stockés sur l’hôte dans un répertoire géré par Docker Engine dédiés aux données persistantes (base de données, …), les bind mounts qui montent un emplacement fichier/dossier défini par l’utilisateur sur l’hôte dans le conteneur (préférable si on souhaite modifier/lire aisément ces contenus) et les tmpfs mounts qui créent un filesystem temporaire en mémoire pour permettre à des conteneurs de partager des données sans écriture disque, comme pour un système de cache.
Pour notre cas, nous aurons besoin de stocker les données suivantes sur l’hôte :
- Base de données : il s’agit ici d’un fichier Sqlite stocké dans le projet Website Data. Comme il n’est pas modifié par l’application elle-même qui ne fait que des requêtes en lecture mais seulement livré à partir du projet Gitlab, il sera pertinent de mettre en place un bind mount afin de pouvoir accéder au fichier dans le conteneur et le remplacer.
- Articles : comme pour la base de données, il faut prévoir un bind mount afin de pouvoir régulièrement mettre à jour les articles (pages HTML et images) sans livrer de nouvelle image Docker de l’application.
- Logs : là aussi un bind mount s’impose pour pouvoir directement lire les logs sans entrer dans le conteneur, et stocker l’historique sur l’hôte.
Créer le Dockerfile
Forts de toutes ces informations, nous allons maintenant pouvoir créer le Dockerfile qui contient les instructions permettant de générer l’image Docker de l’application.
La première question à se poser et de déterminer de quelle image de base part-on pour initier notre environnement. Il paraît pertinent d’utiliser l’image Alpine Linux pour sa légèreté (un peu plus de 3 Mb seulement en format compressé !) tout en fournissant les bibliothèques essentielles pour faire tourner une application.
Attention ! L’image Docker Alpine contient certaines limitations qui peuvent poser des problèmes selon votre cas d’utilisation. Au-delà du nombre limité de packages disponibles, il est par exemple impossible de créer des users faisant plus de 8 caractères.
Nous pouvons donc proposer le Dockerfile suivant :
# Paramètres fournies lors du build avec une valeur par défaut
ARG ALPINE_VERSION=3.20.0
# Image de base utilisée pour générer la nôtre
FROM alpine:${ALPINE_VERSION}
# Variables d'environnement nécessitées par l'application
ENV SITE_PORT=8080
ENV SITE_LANGUAGES="fr,en"
ENV MYWEBSITE_PATH="/srv/mywebsite"
ENV STATIC_ASSETS_PATH="${MYWEBSITE_PATH}/web/static"
ENV TEMPLATES_PATH="${MYWEBSITE_PATH}/web/template"
ENV DATA_PATH="${MYWEBSITE_PATH}/data"
ENV DATABASE_NAME="mywebsite.db"
ENV LOG_PATH="/var/log/mywebsite"
ENV CONFIG_PATH="/etc/mywebsite"
# Fichiers/répertoires copiés de l'hôte vers l'image
ADD package.tgz /tmp
COPY deployments/docker/entrypoint.sh /
COPY deployments/docker/logrotate.d /tmp/logrotate.d/
# Commandes du build de l'image
RUN \
# Extraction et installation de l'application
# On ne copie pas le répertoire package/data parce qu'il sera rempli
# plus tard par un bind mount avec le package du projet website-data
cd /tmp && \
mkdir -p ${MYWEBSITE_PATH} && \
mv package/web ${MYWEBSITE_PATH} && \
mv package/bin/mywebsite /usr/local/bin/ && \
# Création du lien symbolique ${STATIC_ASSETS_PATH}/images/articles
# vers ${DATA_PATH}/articles/images
ln -sf ${DATA_PATH}/articles/images ${STATIC_ASSETS_PATH}/images/articles && \
# Donner les droits d'exécution au script entrypoint.sh
chmod +x /entrypoint.sh && \
# Créer le répertoire de log de l'application
mkdir -p ${LOG_PATH} && \
# Installer curl pour le healthcheck
apk update && \
apk --no-cache add curl && \
# Configurer la timezone du conteneur
apk --no-cache add tzdata && \
# Installer et configurer logrotate
apk --no-cache add logrotate && \
mkdir -p /etc/logrotate.d && \
mv /tmp/logrotate.d/* /etc/logrotate.d/ && \
logrotate -f /etc/logrotate.conf && \
# Purger le répertoire d'installation
rm -rf /tmp/*
# Exposer le port tcp que l'application écoute
EXPOSE ${SITE_PORT}
# Script entrypoint qui sera exécuté lorsque
# le conteneur sera créé
ENTRYPOINT ["/entrypoint.sh"]
Quelques remarques sur le contenu du Dockerfile :
- l’argument
ALPINE_VERSIONpeut être fourni de la sorte lors du build de l’image, sinon il sera initialisé à la valeur indiquée dans sa déclaration :docker build --build-arg ALPINE_VERSION=3.20.0 . - les variables d’environnement
ENVseront également disponibles dans le conteneur, et peuvent être surchargées à son lancement avec la commande docker run - la commande
ADDa été choisie pour l’archivepackage.tgzcar elle en effectue automatiquement l’extraction dans le répertoire cible; sinon il est recommandé d’utiliser la commandeCOPYpour effectuer une copie. - le contenu de la commande
RUNdoit être indiqué sur une seule ligne, d’où l’utilisation de&& \à la fin de chaque ligne de code du Dockerfile - l’application est lancée par le script
entrypoint.shdans la directiveENTRYPOINTqui spécifie une commande toujours exécutée au démarrage du conteneur. On aurait pu obtenir le même résultant avec la directiveCMDqui spécifie des arguments fournis à l’ENTRYPOINT(qui est/bin/sh -cpar défaut).
La rédaction du Dockerfile doit suivre quelques bonnes pratiques, dont la principale est de limiter le nombre de commandes
RUNau strict nécessaire afin d’éviter de créer trop de couches (layers) pour conserver une image légère.
Un point doit toutefois attirer l’attention : l’utilisateur qui fera fonctionner l’application à l’intérieur du conteneur sera root, et ceci peut avoir des implications en terme de sécurité. C’est pourquoi nous allons voir comment modifier le Dockerfile afin que le conteneur soir exécuté avec un autre utilisateur.
Dans le cas de notre application, exécuter le conteneur avec
rootne pose pas de problème car nous utilisons Docker rootless qui fait que le démon Docker est exécuté avec un utilsateur sans droits particuliers sur l’hôte.
Dockerfile avec utilisateur non-root :
ARG ALPINE_VERSION=3.20.0
FROM alpine:${ALPINE_VERSION}
# User et group id de l'utilisateur qui exécutera l'application
ARG USER_ID=1000
ARG GROUP_ID=1000
COPY deployments/docker/logrotate.d /tmp/logrotate.d/
RUN \
# Création de l'utilisateur website et attribution de ses droits
if [ ${USER_ID:-0} -ne 0 ] && [ ${GROUP_ID:-0} -ne 0 ]; then \
addgroup -S -g $GROUP_ID website && adduser -S -s /bin/sh -u $USER_ID website -G website; else \
addgroup -S website && adduser -S -s /bin/sh website -G website; fi && \
mkdir -p /home/website/bin && chown -R website:website /home/website/bin && \
# Installer curl pour le healthcheck
apk update && \
apk --no-cache add curl && \
# Configurer la timezone du conteneur
apk --no-cache add tzdata && \
# Installer et configurer logrotate
apk --no-cache add logrotate && \
mkdir -p /etc/logrotate.d && \
mv /tmp/logrotate.d/* /etc/logrotate.d/ && \
logrotate -f /etc/logrotate.conf && \
# Purger le répertoire d'installation
rm -rf /tmp/*
# Changement d'utilisateur pour déployer l'application
# et la lancer dans le conteneur
USER website
# Variables d'environnement de l'utilisateur website
ENV PATH="${PATH}:/home/website/bin"
ENV SITE_PORT=8080
ENV SITE_LANGUAGES="fr,en"
ENV WEBSITE_SRV_PATH="/home/website/srv"
ENV STATIC_ASSETS_PATH="${WEBSITE_SRV_PATH}/web/static"
ENV TEMPLATES_PATH="${WEBSITE_SRV_PATH}/web/template"
ENV DATA_PATH="${WEBSITE_SRV_PATH}/data"
ENV DATABASE_NAME="mywebsite.db"
ENV LOG_PATH="${WEBSITE_SRV_PATH}/log"
ENV CONFIG_PATH="${WEBSITE_SRV_PATH}/conf"
# Définition du répertoire de base dans lequel seront
# exécutées les commandes RUN
WORKDIR /home/website
# Copie en précisant l'attribution de droits dans le conteneur
COPY --chown=website:website package.tgz /home/website
COPY --chown=website:website --chmod=755 deployments/docker/entrypoint.sh /home/website/bin
RUN \
# Extraction et installation de l'application
# On ne copie pas le répertoire package/data parce qu'il sera rempli
# plus tard par un bind mount avec le package du projet website-data
tar xzf package.tgz && \
mkdir -p $WEBSITE_SRV_PATH && mv package/web $WEBSITE_SRV_PATH && \
mv package/bin/mywebsite ~/bin/ && \
# Création du lien symbolique ${STATIC_ASSETS_PATH}/images/articles
# vers ${DATA_PATH}/articles/images
ln -sf ${DATA_PATH}/articles/images ${STATIC_ASSETS_PATH}/images/articles && \
# Créer le répertoire de log de l'application
mkdir -p ${LOG_PATH} && \
# Purger le répertoire d'installation
rm -rf package*
# Script entrypoint qui sera exécuté lorsque
# le conteneur sera créé
ENTRYPOINT ["entrypoint.sh"]
Quelques points à relever ;
ARG USER_ID/GROUP_ID=1000: on laisse la main à l’utilisateur pour déterminer l’user/group id de l’utilisateur qui est créé (avec une valeur par défaut de1000). Il est en effet préférable que ces valeurs correspondant à celles de l’utilisateur qui lancera le conteneur sur l’hôte, notamment pour des raisons de droits sur les bind mounts.- Les variables d’environnement ont logiquement été transférés à l’utilisateur
website. COPY --chown=website:website --chmod=755 ...: les commandes de copie doivent contenir l’attribution des droits si on veut qu’ils reviennent à un utilisateur autre que root, même après avoir indiquéUSER website.
Et voilà ! Nous sommes maintenant en mesure de tester l’exécution de notre application dans un conteneur.
Définir le script entrypoint.sh
Nous l’avions défini dans notre Dockerfile avec la commande ENTRYPOINT qui l’exécute au lancement du conteneur, nous allons maintenant voir le contenu du script entrypoint.sh.
Son objectif est de :
- lancer l’application en tâche de fond
- récupérer les sorties standard et erreur dans un fichier de log
- transmettre le code de sortie de l’application au conteneur
#!/bin/sh
set -e
# Attraper le signal SIGTERM et le transmettre au processus fils
trap 'kill -TERM $PID' TERM
# Lancer l'application Go en tâche de fond et récupérer le PID
mywebsite 2>&1 | tee -a ${LOG_PATH}/mywebsite.log &
PID=$!
wait $PID
# Sortir avec le même code d'exécution que le processus fils
exit $?
Tester le build et l’exécution de l’image Docker
Générer l’image Docker et exécuter le conteneur
De façon générale, il est préférable de placer le Dockerfile à la racine du projet dont il doit assurer le build, de façon à avoir accès aux fichiers/dossiers qu’il devra copier dans le conteneur.
En effet, il est impossible d’indiquer un chemin de type ../target ou absolu tel que /path/to/target dans les instructions COPY ou ADD du Dockerfile.
Dès lors que nous avons placé le Dockerfile à la racine du projet, nous pouvons lancer le build de l’image de notre application :
$ docker build -t mywebsite .
-tindique le nom de l’image avec lequel elle sera taggée (un taglatestlui sera attribué par défaut). Même si nous ne la publions pas encore, ce sera utile pour l’identifier dans notre instance Docker.définit le contexte du build qui est donc le répertoire courant.
Nous obtenons une sortie semblable à celle-ci :
Si nous utilisons Docker Desktop, nous pouvoir apparaître l’image dans la liste de celles disponibles dans l’instance Docker :
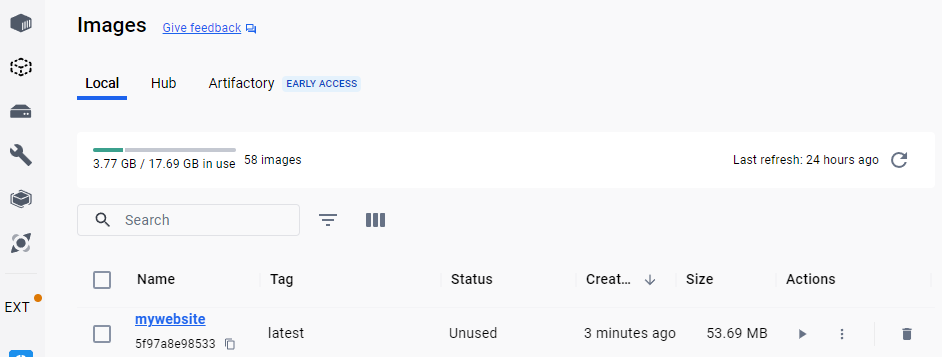
Nous pouvons maintenant lancer le conteneur avec la commande docker run :
$ docker run -d -p 8080:8080 --name mywebsite mywebsite:latest
-d: le conteneur est exécuté en mode détaché, cela signifie qu’il tourne en tâche de fond et que l’on peut utiliser le terminal-p 8080:8080: cette option associe le port 8080 de l’hôte avec le port 8080 du conteneur, ce qui permet d’accéder de l’extérieur à l’application tournant dans le conteneur--name mywebsite: nous attribuons ainsi un nom au conteneur afin de pouvoir l’identifier plus facilement, sinon il reçoit un nom aléatoire.mywebsite:latest: il s’agit du nom de l’image précédemment générée et du tag qui lui a été attribué
On peut alors accéder à l’application en se connectant à l’URL http://localhost:8080 si on a lancé Docker sur la machine locale.
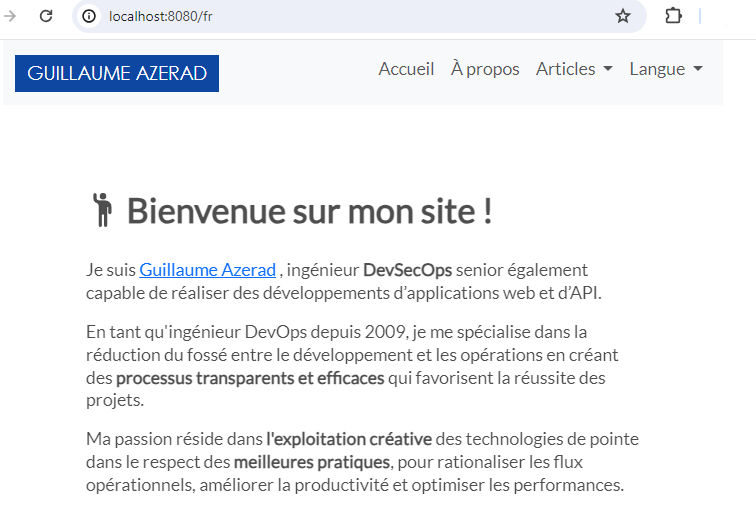
Pour arrêter le conteneur puis le supprimer, il faut exécuter les deux commandes suivantes :
$ docker stop mywebsite
$ docker rm mywebsite
Créer un environnement de test complet avec Docker Compose
Le répertoire sample du projet Website Core propose un environnement de test où l’application mywebsite est exécutée derrière un proxy inversé Nginx qui la sert sur l’URL https://mywebsite.perso.com (à condition d’avoir associé mywebsite.perso.com avec l’IP du serveur correspondant dans son fichier hosts).
Le fichier docker-compose.yml correspondant assure le build de l’image docker mywebsite à partir du contexte du répertoire racine du projet (défini de façon relative avec ../../..) et le lancement du conteneur correspondant derrière le proxy inversé.
services:
mywebsite:
#image: mywebsite:latest
build: ../../..
container_name: mywebsite
restart: always
networks:
- frontend
expose:
- "8080"
volumes:
- ./mywebsite/log:/var/log/mywebsite
- ./mywebsite/data:/srv/mywebsite/data:rw
reverse_proxy:
image: nginx:1.26
container_name: reverse_proxy
restart: always
networks:
- frontend
ports:
- 80:80
- 443:443
volumes:
- ./nginx/conf/nginx.conf:/etc/nginx/conf.d/default.conf
- ./nginx/certs/mywebsite.crt:/etc/ssl/certs/mywebsite.crt
- ./nginx/certs/mywebsite.key:/etc/ssl/private/mywebsite.key
- ./nginx/log:/var/log/nginx
networks:
frontend:
driver: bridge
Nous remarquons que nous avons introduit ici la notion de volume :
volumes:
- ./mywebsite/log:/var/log/mywebsite
- ./mywebsite/data:/srv/mywebsite/data:rw
Définis de la sorte, en montant un répertoire de l’hôte avec un à l’intérieur du conteneur, il s’agit en réalité de bind mounts, et ils correspondent aux répertoires identifiées dans la section Déterminer les données persistantes.
On lance cet environnement se plaçant au niveau du fichier docker-compose.yml et en exécutant la commande suivante :
$ docker compose up -d
Et on l’arrête comme ceci :
$ docker compose down
Intégration et déploiement continus avec Gitlab CI
L’objet de cette section est de définir les jobs d’une pipeline CI/CD Gitlab afin d’effectuer les tâches suivantes :
- générer l’image Docker de l’application et la publier sur Docker Hub
- déployer le conteneur correspondant sur nos environnements où fonnctionne l’application
Gitlab propose un container registry qui permet de publier des images Docker pour chaque projet. Nous ne l’utilisons cependant pas ici puisque notre image doit être accessible hors du réseau privé sur lequel tourne notre instance Gitlab.
Génération de l’image Docker et publication sur Docker Hub
Nous considérons ici que notre instance Gitlab exécute ses jobs avec un runner Docker, qui est généralement conseillé.
Le défi ici consiste à pouvoir exécuter des commandes Docker (telles que docker build ou docker push) à l’intérieur du conteneur dans lequel est exécuté le job.
Les premières options proposées consistent à :
- Choisir finalement d’exécuter le job avec un runner shell, ce qui nécessiterait de créer un runner supplémentaire.
- Utiliser Docker-in-Docker (dind) mais cela nécessite une élévation de privilèges pour les conteneurs créés par les runners.
- Utiliser le socket binding pour avoir accès au Docker daemon de l’hôte à l’intérieur des conteneurs.
Hélas, chacune d’entre elles introduit complexité, problématiques de sécurité et limitations; c’est pourquoi nous allons choisir Kaniko pour construire nos images Docker dans des jobs Gitlab CI.
De façon très simple (aucune configuration particulière du runner Gitlab n’est requise), le job de build/publication de l’image Docker se définit ainsi dans le fichier .gitlab-ci.yml du projet Website Core :
publish-docker:
stage: publish
image:
name: gcr.io/kaniko-project/executor:$KANIKO_VERSION
entrypoint: [""]
rules:
- if: $DEPLOY_MODE == "Y"
when: never
- !reference [.rules, tag_release_candidate]
- !reference [.rules, tag_release]
- if: !reference [.rules, latest]
script:
- if [ X"$CI_COMMIT_TAG" == "X" ]; then IMAGE_TAG="latest"; else IMAGE_TAG=$CI_COMMIT_TAG; fi
- echo "Info - the image will be pushed with '$IMAGE_TAG' tag"
- |-
echo "
{
\"auths\":{
\"${DOCKERHUB_REGISTRY}\":{
\"auth\":\"$(printf "%s:%s" "${DOCKERHUB_USER}" "${DOCKERHUB_PASSWORD}" | base64 | tr -d '\n')\"
}
}
}" > /kaniko/.docker/config.json
- /kaniko/executor
--context "$CI_PROJECT_DIR"
--build-arg ALPINE_VERSION=$ALPINE_VERSION
--dockerfile "${CI_PROJECT_DIR}/Dockerfile"
--destination "${DOCKERHUB_USER}/mywebsite:${IMAGE_TAG}"
Il suffit de définir les variables CI/CD suivantes, soit dans le fichier .gitlab-ci.yml soit dans l’UI Gitlab (au niveau projet/groupe/instance) :
DOCKERHUB_REGISTRY: l’URL de publication des images sur Docker Hub. Il faut indiquer ici la valeurhttps://index.docker.io/v1/et non celle du dépôt sur lequel sera publié l’image.DOCKERHUB_USER: le nom de compte utilisé pour publier l’image sur Docker HubDOCKERHUB_PASSWORD: le mot de passe correspondant
Ces variables sont donc indiquées sous format json dans le fichier de configuration de Kaniko /kaniko/.docker/config.json.
La commande de build de l’image reçoit ici les paramètres suivants :
--context "$CI_PROJECT_DIR": le contexte semblable à celui de la commandedocker buildet qui correspond à la racine du projet où se trouve le Dockerfile--build-arg ALPINE_VERSION=$ALPINE_VERSION: les arguments qui viendront enrichir les variables définies par le mot-clefARGdans le Dockerfile.--dockerfile "${CI_PROJECT_DIR}/Dockerfile": on définit précisément l’emplacement du Dockerfile ici.--destination "${DOCKERHUB_USER}/mywebsite:${IMAGE_TAG}": la destination de publication de l’image Docker où sont indiqués le dépôt, le nom de l’image et son tag.
Nous obtenons alors la sortie suivante dans la log de la pipeline Gitlab :
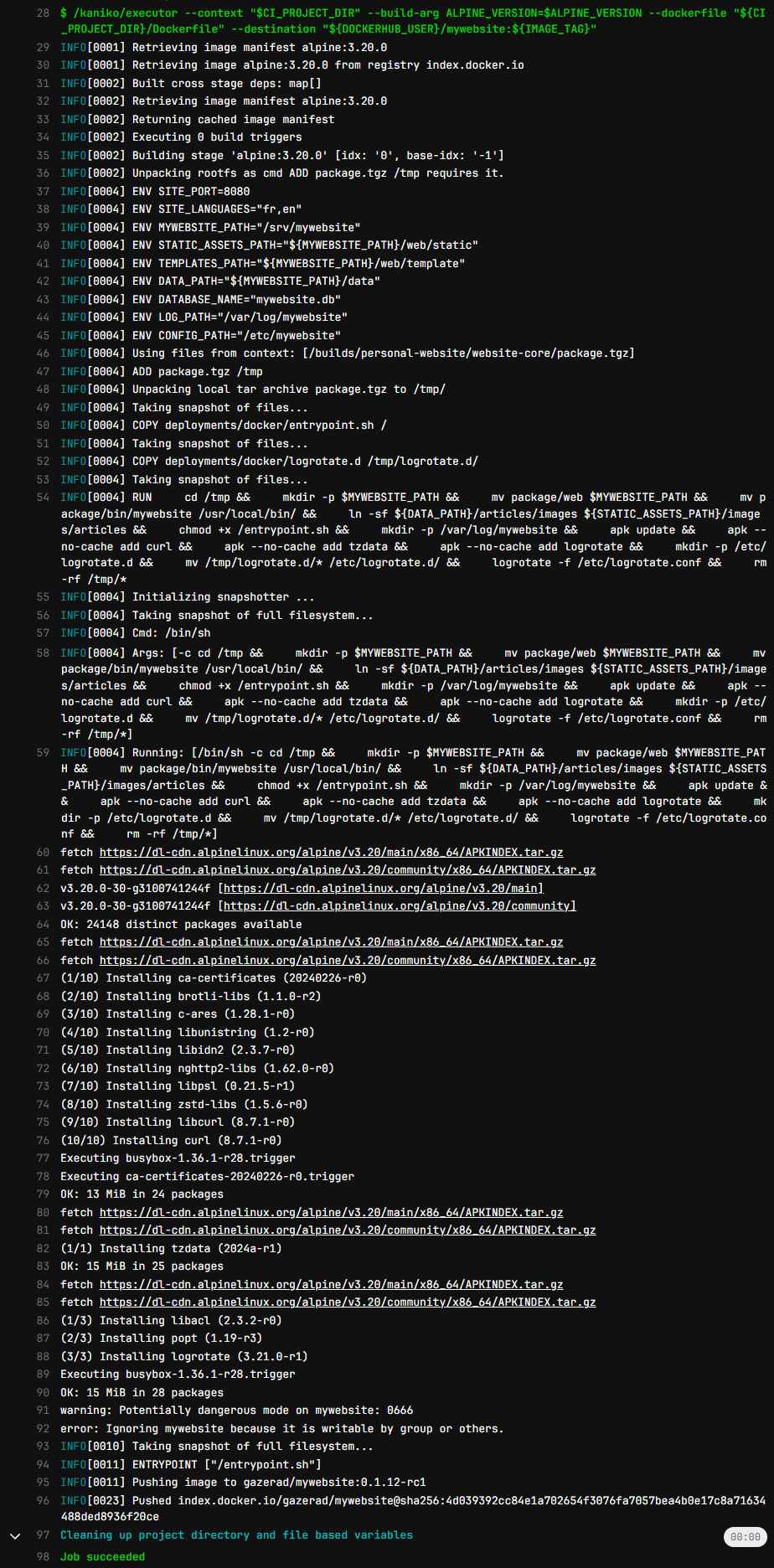
L’image Docker est bien générée est publiée dans le dépôt gazerad/mywebsite sur Docker Hub.
Déploiement du conteneur de l’application
Le déploiement de l’application, basé sur Gitlab CI/Ansible/Docker, est détaillé dans l’article Déploiement continu avec Gitlab et Ansible.
En résumé, nous disposons dans la pipeline CI/CD d’un job qui va exécuter un playbook Ansible assurant le déploiement et le lancement de l’application ainsi que du proxy inversé qui lui est associé.
Nous allons nous focaliser ici sur le rôle Ansible application des déploiements définis dans le projet Website Core.
Les tâches du rôle consistent tout d’abord, après avoir correctement configuré l’environnement, à déployer le fichier Docker Compose où est défini le service qui exécutera l’application :
# roles/application/tasks/main.yml
- name: Deploy docker-compose file
template:
src: templates/docker-compose.yml.j2
dest: "{{ application_dir }}/docker-compose.yml"
mode: '600'
owner: mywebsite
group: mywebsite
Le fichier docker-compose.yml est défini sous forme de template contenant des variables enrichies par le playbook Ansible :
# {{ ansible_managed | comment }}
services:
mywebsite:
# mywebsite_version variable is set from environment variable MYWEBSITE_VERSION
image: gazerad/mywebsite:{{ mywebsite_version }}
container_name: mywebsite
restart: always
networks:
- frontend
expose:
- "8080"
volumes:
- "{{ mywebsite_dir }}/log:/var/log/mywebsite"
- "{{ mywebsite_dir }}/data:/srv/mywebsite/data"
- /etc/localtime:/etc/localtime:ro
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/fr"]
interval: 30s
timeout: 10s
retries: 3
labels:
autoheal: true
autoheal:
# To restart the unhealthy containers with label 'autoheal: true' defined
# https://github.com/willfarrell/docker-autoheal
image: willfarrell/autoheal:{{ versions.autoheal }}
container_name: autoheal
restart: always
networks:
- frontend
volumes:
# Still XDG_RUNTIME_DIR depends from the docker rootless user definition
- "{{ xdg_runtime_dir }}/docker.sock:/var/run/docker.sock:ro"
- /etc/localtime:/etc/localtime:ro
environment:
AUTOHEAL_INTERVAL: '30'
AUTOHEAL_DEFAULT_STOP_TIMEOUT: '10'
AUTOHEAL_CONTAINER_LABEL: 'autoheal'
CURL_TIMEOUT: '10'
Le service autoheal, facultatif dans l’absolu, a pour objet d’assurer une surveillance du service mywebsite de l’application et son redémarrage sous les conditions définies dans sa section environment.
Ensuite, comme nous l’avions identifié dans l’analyse du contenu à déployer, le rôle application importe des tâches qui permettent de modifier le bind mount contenant la base de données et les articles en déployant le package du projet Website Data.
# roles/application/tasks/main.yml
- import_tasks: website_data.yml
tags:
- website-data
# roles/application/tasks/website_data.yml
- name: Set website data package version
set_fact:
website_data_pkg_ref: "{{ lookup('env', 'WEBSITE_DATA_PKG_REF') }}"
become_user: mywebsite
- name: Download and extract website data package to target
unarchive:
src: "{{ external_gitlab_api_v4_url }}/projects/{{ external_website_data_id }}/packages/generic/data/{{ website_data_pkg_ref }}/data.tgz"
dest: "{{ mywebsite_dir }}"
remote_src: yes
become_user: mywebsite
Enfin, les handlers assurant le redémarrage de Docker Compose sont appelés à la fin des tâches du rôle application :
# roles/application/tasks/main.yml
- debug:
msg: "Trigger docker compose stop"
notify: Stop docker compose
changed_when: true
- debug:
msg: "Trigger docker compose start"
notify: Start docker compose
changed_when: true