
Cet article fait partie d’une série consacrée à la scalabilité sur un cloud hybride avec Azure :
- Partie 1: l’infrastructure
- Partie 2: la mise à l’échelle avec une fonction Azure
- Partie 3: les alertes de supervision
Introduction
Les deux premiers articles de la série sur le cloud hybride nous ont permis dans un premier temps de mettre en place l’infrastructure associant le réseau privé et le cloud public Azure, puis d’implémenter le mécanisme de scalabilité de l’application basé sur une fonction Azure.
Il reste maintenant à établir le déclenchement automatique des créations/suppressions de VM sur le cloud en fonction des évènements de supervision. C’est ce que nous allons aborder ici en configurant une stack de supervision (monitoring) Grafana / Prometheus / Alertmanager.
Cas d’utilisation
Rappelons les règles de supervision de la VM locale que nous nous étions fixées pour déterminer la création ou suppression de VM sur le cloud Azure :
- CPU > 70% sur les 5 dernières minutes => création de VM Azure (jusqu’à deux maximum)
- CPU < 30% sur la dernière heure avec présence d’au moins un pic > 70% (par pas de 5 minutes) => suppression de VM Azure
D’autre part, nous rappelons le mécanisme de scalabilité mis en place qui relie ces alertes de supervision aux actions de création/suppression de VM sur Azure.
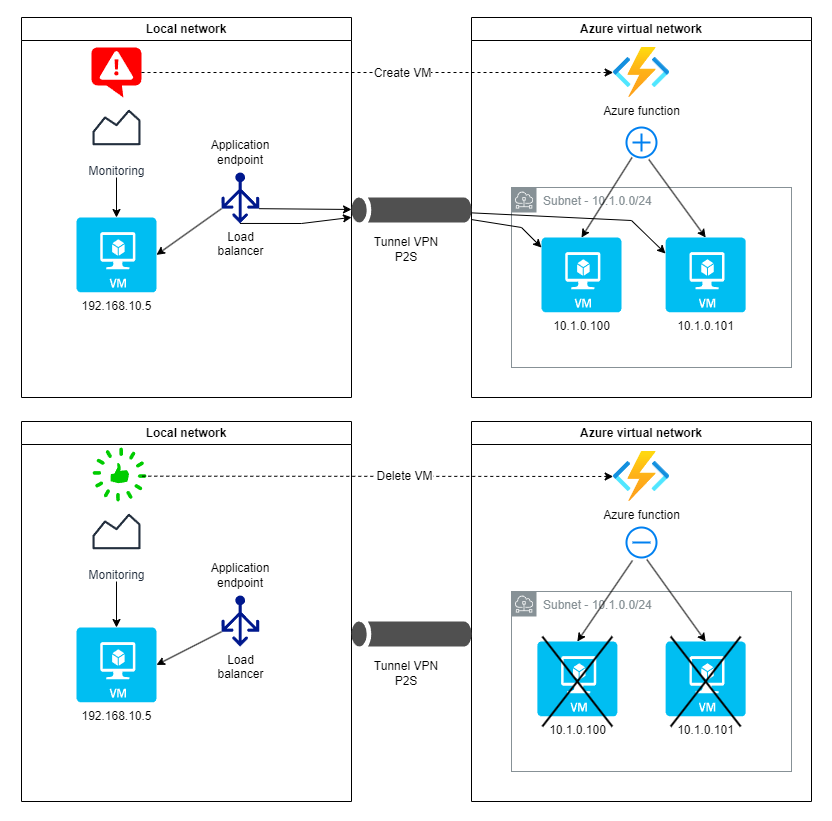
Nous allons donc examiner comment générer les évènements de supervision et les faire interagir avec Azure Functions pour assurer la scalabilité de notre application.
Installation de la supervision locale
Comme indiqué, nous allons choisir d’installer une stack Grafana / Prometheus / Alertmanager pour la gestion de la supervision (Prometheus), la définition d’alertes (Alertmanager) et l’affichage graphique des données (Grafana). Les métriques systèmes du serveur où tourne l’application sont fournies par Node exporter qui communique directement avec Prometheus pour leur traitement.
Récolte des métriques avec Node exporter
Notre premier objectif est d’effectuer la surveillance des ressources système (CPU, RAM, stockage, réseau, …) du serveur du réseau local sur lequel tourne notre application.
Node exporter est un outil open source, principalement utilisé dans les environnements de surveillance de systèmes, pour collecter et exposer des métriques système sur des serveurs Linux. Il est spécifiquement conçu pour être utilisé avec Prometheus, une solution de monitoring et d’alerting.
De façon très simple, Node exporter peut se déployer à l’aide de Docker Compose et communiquer les données récoltées sur le port 9100 (par défaut). Nous remarquerons que dans notre cas, nous constituons un fichier docker-compose.yml commun avec l’application tournant sur le serveur que nous souhaitons superviser.
Puisque nous utilisons une installation conteneurisée de Node exporter, nous devons définir avec attention les volumes en disposant de droits suffisants sur l’hôte afin de superviser les métriques du serveur et non celles du conteneur lui-même.
services:
# Application web du serveur
application:
image: crccheck/hello-world
container_name: application
ports:
- "80:8000"
# Service Node Exporter
node-exporter:
image: prom/node-exporter:v1.8.1
container_name: node_exporter
# On expose le port 9100 qui sera accessible pour Prometheus
# déployé sur un autre serveur dédié à la supervision
ports:
- "9100:9100"
volumes:
# Les volumes suivants définissent les répertoires systèmes
# du serveur où seront récoltées les métriques
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
# Ce volume permet de corriger une erreur éventuelle de lancement
- /srv/app/node-exporter/textfile_collector:/var/lib/node_exporter/textfile_collector:ro
# On associe ici la date système du serveur et celle du conteneur
- /etc/localtime:/etc/localtime:ro
command:
# Paramètres de lancement de node-exporter
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--path.rootfs=/rootfs'
- '--collector.textfile.directory=/var/lib/node_exporter/textfile_collector'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
restart: always
Une fois l’environnement lancé avec la commande docker compose up -d, nous avons accès à une page sur le port 9100 du serveur (ici d’adresse IP 192.168.10.5).
Déploiement de Grafana / Prometheus / Alertmanager
Le déploiement des services effectuant l’analyse (tableau de bord, définition d’alertes) des données système remontées par Node exporter se fait également avec Docker Compose sur un autre serveur dédié à la supervision.
services:
grafana:
image: grafana/grafana:10.4.4
container_name: grafana
ports:
- "3000:3000"
networks:
- monitoring
volumes:
- grafana-data:/var/lib/grafana
- /etc/localtime:/etc/localtime:ro
# - /home/guaz/certs/perso/perso.com.key:/etc/grafana/grafana.key:ro
# - /home/guaz/certs/perso/perso.com.crt:/etc/grafana/grafana.crt:ro
environment:
# Setting admin account credentials
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: NV1lgz7ViL4xibQ8NtqV
# Setting Grafana server URL
# GF_SERVER_DOMAIN: "grafana.perso.com"
# GF_SERVER_ROOT_URL: "https://grafana.perso.com/"
restart: always
prometheus:
image: prom/prometheus:v2.53.0
container_name: prometheus
ports:
- "9090:9090"
networks:
- monitoring
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./prometheus/alert.rules.yml:/etc/prometheus/alert.rules.yml
- prometheus-data:/prometheus
- /etc/localtime:/etc/localtime:ro
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
- '--web.enable-lifecycle'
restart: always
alertmanager:
image: prom/alertmanager:v0.27.0
container_name: alertmanager
ports:
- "9093:9093"
networks:
- monitoring
volumes:
- alertmanager-data:/data
- ./alert-manager/alertmanager.yml:/config/alertmanager.yml
- /etc/localtime:/etc/localtime:ro
command: --config.file=/config/alertmanager.yml --log.level=debug
volumes:
grafana-data:
prometheus-data:
alertmanager-data:
networks:
monitoring:
driver: 'bridge'
Quelques remarques sur l’installation :
- Les ports exposés pour chacun des services sont :
3000pour Grafana,9090pour Prometheus et9093pour Alertmanager. Nous avons choisi de les ouvrir directement vers l’extérieur pour avoir accès à leurs interfaces respectives. Cela n’est par contre pas nécessaire pour qu’ils communiquent entre eux puis qu’ils appartiennent au même réseau Dockermonitoring. - Chaque service a besoin d’un volume afin de conserver les données :
grafana-data,prometheus-data,alertmanager-data. - La configuration de Grafana se gère par variables d’environnement alors que Prometheus et Alertmanager nécessitent de créer des volumes bind mount pour leurs fichiers de configuration.
- Le volume montant
/etc/localtimen’a d’autre finalité que de faire en sorte que les conteneurs et l’hôte partagent la même heure système. - Les paramètres de la commande de lancement de Prometheus permettent de s’assurer des points suivants :
--config.file: spécification du fichier de configuration dans un volume permettant sa modification de l’extérieur--storage.tsdb.path: Le chemin de stockage des données est correctement assigné au volume persistant.-web.enable-lifecycle: Cette option permet de recharger la configuration sans redémarrer le conteneur, ce qui est utile pour appliquer des changements dynamiques.s
Mise en oeuvre de l’alerting
Configuration de Prometheus
Nous avons vu précédemment que la configuration de Prometheus se compose de deux fichiers : /etc/prometheus/prometheus.yml et /etc/prometheus/alert.rules.yml
(soit ./prometheus/prometheus.yml et ./prometheus/alert.rules.yml sur le serveur de supervision à l’emplacement de Docker Compose).
prometheus.yml
global:
scrape_interval: 1m
rule_files:
- /etc/prometheus/alert.rules.yml
alerting:
alertmanagers:
- scheme: http
- static_configs:
- targets: ['alertmanager:9093']
scrape_configs:
- job_name: 'node'
static_configs:
- targets: ['vm-debian-3:9100']
La configuration générale de Prometheus définit les élements suivants:
scrape_interval: l’intervalle de récupération des métriques (ici, une minute)rule_files: le fichier contenant les règles d’alertesalerting: la partie définissant l’envoi des alertes, ici vers le servicealertmanageraccessible sur le port 9093scrape_configs: la configuration des serveurs à superviser. Ici, nous n’avons que la VM de notre application nomméevm-debian-3sur laquelle Node exporter est accessible par le port 9100
alert.rules.yml
groups:
- name: cpu_alerts
rules:
- alert: HighCPUUsage
expr: (1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100", mode="idle"}[5m])) * 100 > 70
for: 5m
labels:
severity: critical
annotations:
summary: "High CPU usage detected on instance {{ $labels.instance }}"
description: "The CPU usage on instance {{ $labels.instance }} has been over 70% for more than 5 minutes."
- alert: NormalCPUUsage
expr: |
max_over_time((1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100",mode="idle"}[5m]))[1h:5m]) * 100 > 70
and (1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100", mode="idle"}[1h])) * 100 < 30
for: 1h
labels:
severity: none
annotations:
summary: "CPU back to normal usage on instance {{ $labels.instance }}"
description: "The CPU usage on instance {{ $labels.instance }} has come down under 30% after a peak."
Ce fichier contient donc la définition des alertes d’utilisations de CPU telles que précédemment définies :
- CPU > 70% sur les 5 dernières minutes
- CPU < 30% sur la dernière heure avec présence d’au moins un pic > 70% (par pas de 5 minutes)
Ces alertes sont définies sous le paramètre expr par des expressions PromQL.
Le paramètre de configuration suivant, for, définit un temps d’attente pendant lequel l’alerte doit rester active avant qu’elle ne soit envoyée. Sans cette clause, les alertes
seraient immédiatement envoyées dès leur réception.
Enfin, nous indiquons la sévérité de l’alerte dans les labels, et les annotations ajoutent une définition explicite des alertes.
Sur l’interface de Prometheus (disponible dans notre cas à l’URL http://localhost:9090), nous pouvons voir ces alertes et leur statut.
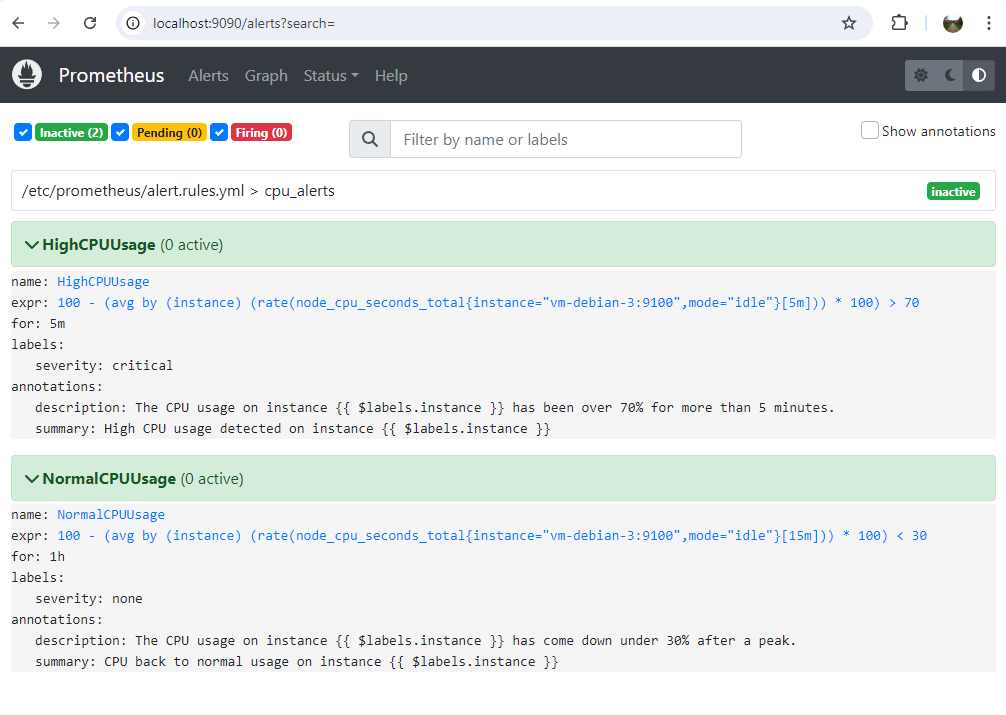
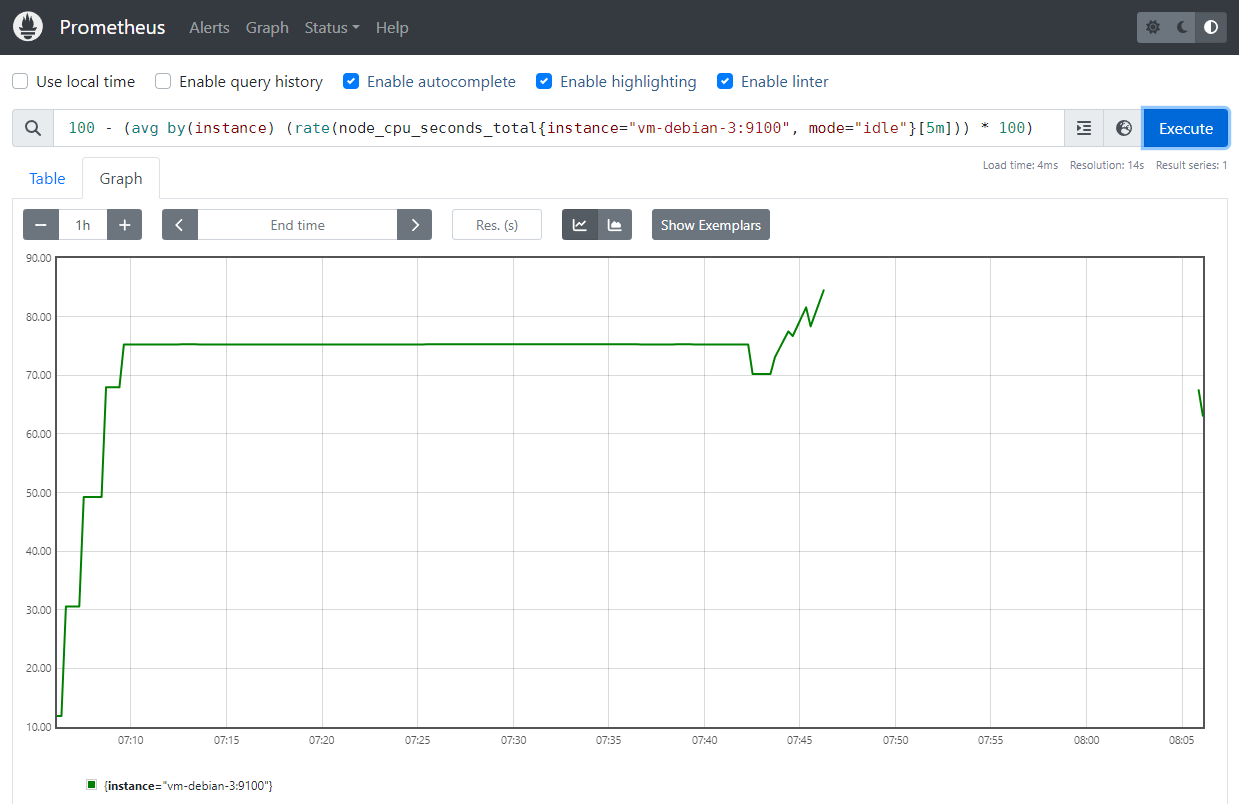
Dans la partie Graph, il est possible de visualiser des métriques en indiquant des expressions PromQL.
Détail de la définition des alertes
Les expressions PromQL définissant les alertes de supervision sont assez complexes à première vue. Nous allons en expliciter quelques éléments ici.
HighCPUUsageexpr: (1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100", mode="idle"}[5m])) * 100rate(node_cpu_seconds_total{instance="vm-debian-3:9100", mode="idle"}[5m]: la fonction rate calcule le taux d’inactivité (idle) moyen du CPU de la VM que nous souhaitons superviser sur les 5 dernières minutes écoulées.(1 - ...) * 100: nous récupérons le taux d’utilisation CPU en soustrayant le précédent résultat de 1, puis nous le multiplions par 100 pour obtenir un pourcentage> 70: vérifie que ce taux d’utilisation CPU dépasse le seuil de 70% afin de déclencher l’alerte
NormalCPUUsageexpr: | (max_over_time((1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100",mode="idle"}[5m]))[1h:5m]) * 100) > 70) and ((1 - rate(node_cpu_seconds_total{instance="vm-debian-3:9100", mode="idle"}[1h])) * 100) < 30)Ici, l’expression se divise en deux parties :
- Détection d’un pic d’utilisation CPU supérieur à 70% dans la dernière heure
1 - rate(...)[5m]: de même que précédemment, nous récupérons le taux d’utilisation CPU moyen par période de 5 minutesmax_over_time((...[1h:5m]): cette fonction capture le pic maximal d’activité CPU observé au cours de la dernière heure avec des intervalles de mesure de 5 minutes ([1h:5m])* 100) > 70: nous nous assurons que ce pic d’activité a été supérieur à 70%
- Vérification que l’utilisation CPU moyenne est retombée sous 30% sur la dernière heure : il s’agit de la même
expression que pour l’alerte
HighCPUUsagemais avec le test< 30.
- Détection d’un pic d’utilisation CPU supérieur à 70% dans la dernière heure
Pour une infrastructure supervisée comprenant plusieurs serveurs, on fait précéder le calcul du taux d’utilisation des ressources en PromQL par
avg by(instance)afin d’obtenir la moyenne par instance :avg by(instance)(rate(node_cpu_seconds_total{instance=~"server1|server2|server3", mode="idle"}[5m]))
De la sorte, l’alerte NormalCPUUsage se déclenche lorsque nous nous assurons d’un retour à la normale de l’utilisation des ressources
de la VM locale sur laquelle est déployée notre application, et entraîne la suppression des VM créées sur le cloud grâce à Alertmanager.
Nous allons maintenant décrire la configuration d’Alertmanager pour associer les tâches souhaitées lorsque les alertes de supervisions sont déclenchées.
Gestion des alertes avec Alertmanager
Nous avons vu que Prometheus a la possibilité de récupérer des métriques système et de générer des alertes à partir d’elles.
Maintenant, Alertmanager va permettre d’exploiter ces alertes en leur associant une tâche. Dans notre cas, nous souhaitons créer/supprimer des VM sur le cloud Azure afin d’implémenter notre stratégie de cloud hybride. Cela sera fait par des appels API à la fonction Azure que nous avons détaillée dans l’article qui lui est consacré.
Regardons maintenant le contenu du fichier de configuration alertmanager.yml :
route:
group_by: ['alertname']
receiver: 'default'
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- receiver: 'create-vm'
matchers:
- alertname = "HighCPUUsage"
- receiver: 'delete-vm'
matchers:
- alertname = "NormalCPUUsage"
receivers:
- name: 'default'
- name: 'create-vm'
webhook_configs:
- url: https://tp-cloud-autoscale-vpn.azurewebsites.net/api/autoscale-vpn?action=create
- name: 'delete-vm'
webhook_configs:
- url: https://tp-cloud-autoscale-vpn.azurewebsites.net/api/autoscale-vpn?action=delete
Ce fichier configure la manière dont les alertes sont traitées et envoyées à des destinations spécifiques (receivers).
La section route définit la manière dont les alertes sont regroupées, attendues, et transmises à des destinations spécifiques appelées “receivers”.
group_by: ['alertname']: les alertes sont regroupées par nom (alertname).receiver: 'default': si une alerte ne correspond à aucune route spécifique, elle est envoyée au receiver ‘default’.group_wait: 30s,group_interval: 5m,repeat_interval: 12h: définissent les délais pour l’envoi et la répétition des alertes.
Sous la clef routes, des routes spécifiques sont définies pour des types d’alertes particuliers, chacune dirigée vers un receiver différent.
create-vm: envoie les alertes HighCPUUsage à un webhook pour créer une VM.delete-vm: envoie les alertes NormalCPUUsage à un webhook pour supprimer une VM.
Enfin, la section receivers définit les URL des webhooks correspondant à chacune des routes.
Alertmanager offre aussi une page web disponible sur le port 9093 du serveur de monitoring.
Test de la mise à l’échelle sur alertes de supervision
Simulation de charge CPU sur le serveur local
Nous allons installer l’outil stress-ng qui permet, sur des systèmes Linux, de soumettre à une charge déterminée le serveur cible.
Sous une distribution Debian, cela se fait très simplement avec la commande suivante :
sudo apt-get install stress-ng
Afin de déclencher l’alerte de supervision HighCPUUsage précédemment définie, nous allons exécuter la commande ci-dessous qui va faire passer l’utilisation de CPU à 75% pour un seul processeur (ce qui est suffisant car le serveur local de notre application est une VM à 1 vCPU).
$ stress-ng -c 1 -l 75
stress-ng: info: [948] defaulting to a 86400 second (1 day, 0.00 secs) run per stressor
stress-ng: info: [948] dispatching hogs: 1 cpu
Logiquement, nous pouvons voir dans Prometheus l’utilisation de CPU moyennée par pas de 5 minutes passer rapidement au-dessus du seuil de 70% censé déclencher l’alerte HighCPUUsage.
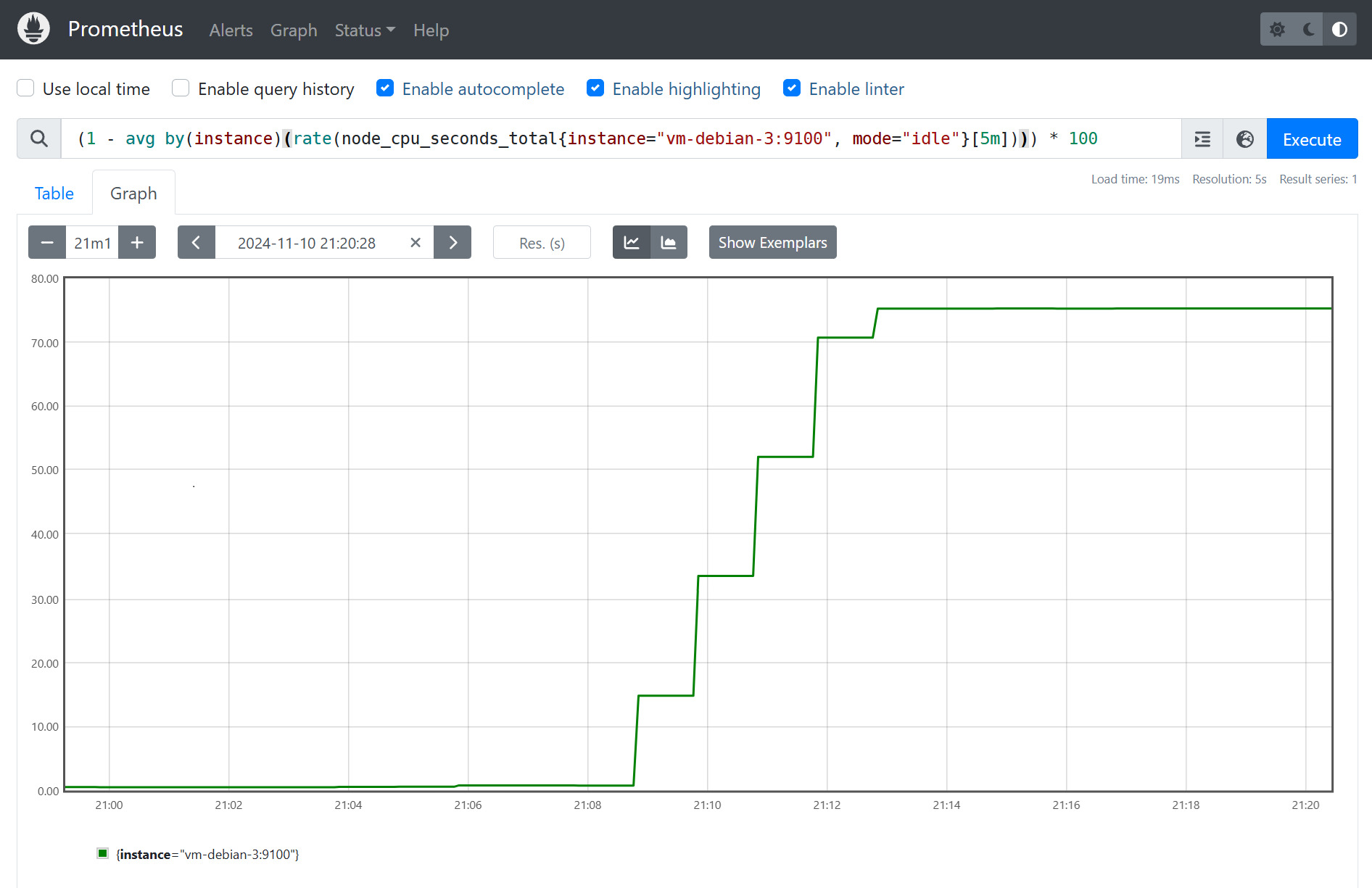
Nous pouvons alors constater que l’alerte est bien émise sur l’interface de Prometheus, et dans un premier temps en état Pending pendant la durée définie pour le paramètre for de la configuration de Prometheus.
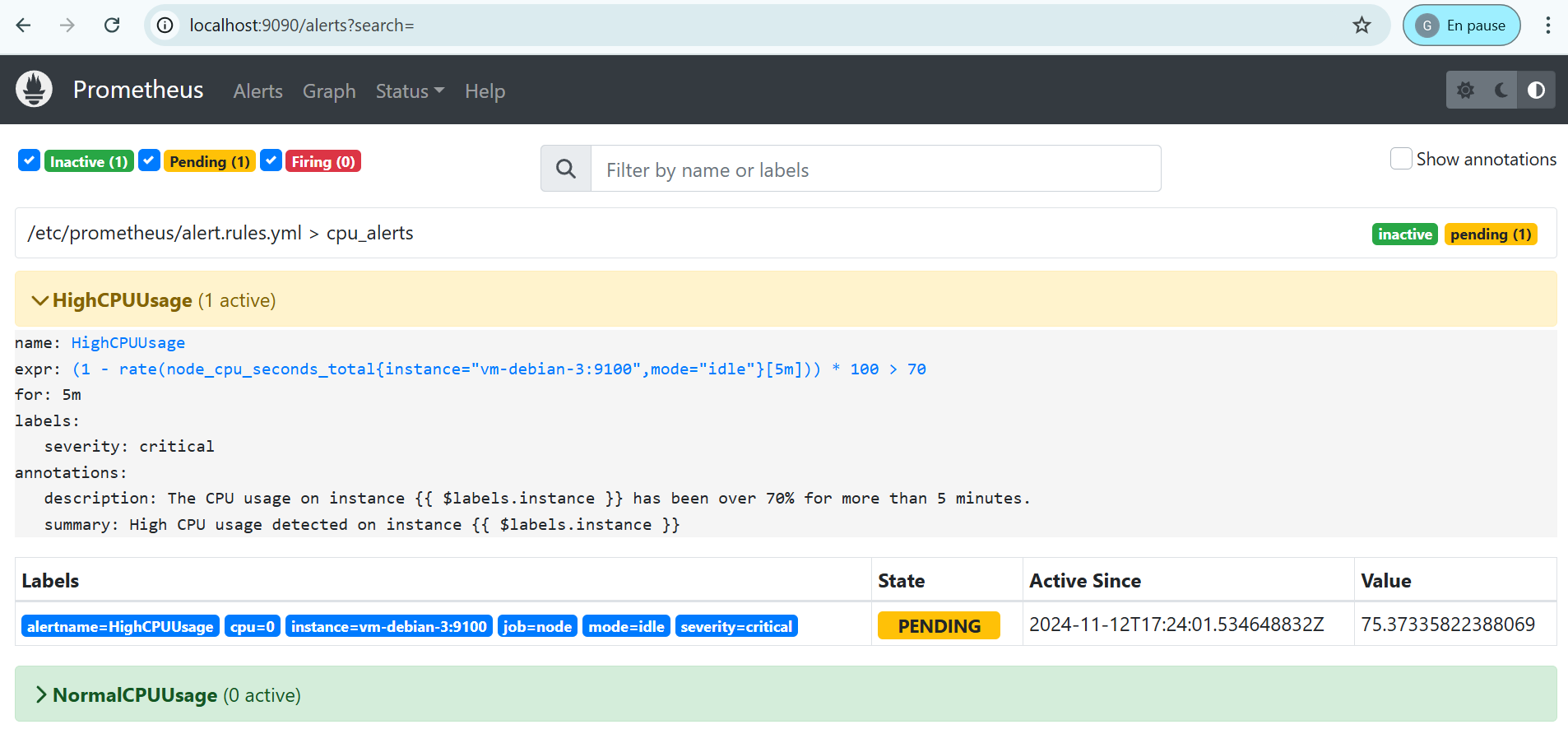
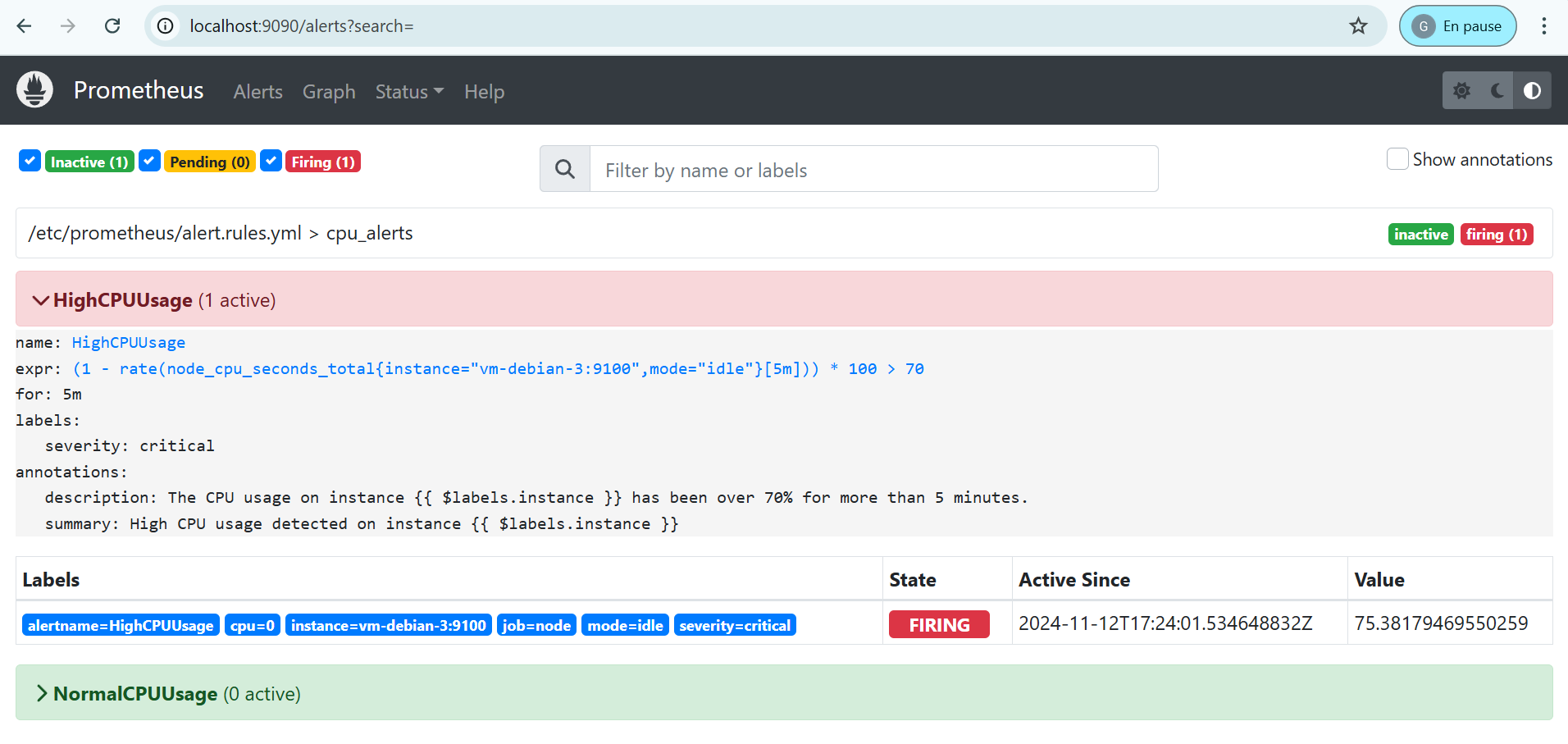
Il faut donc dans notre cas attendre 5 minutes avant que l’alerte ne passe en état Firing signifiant son envoi à Alertmanager.
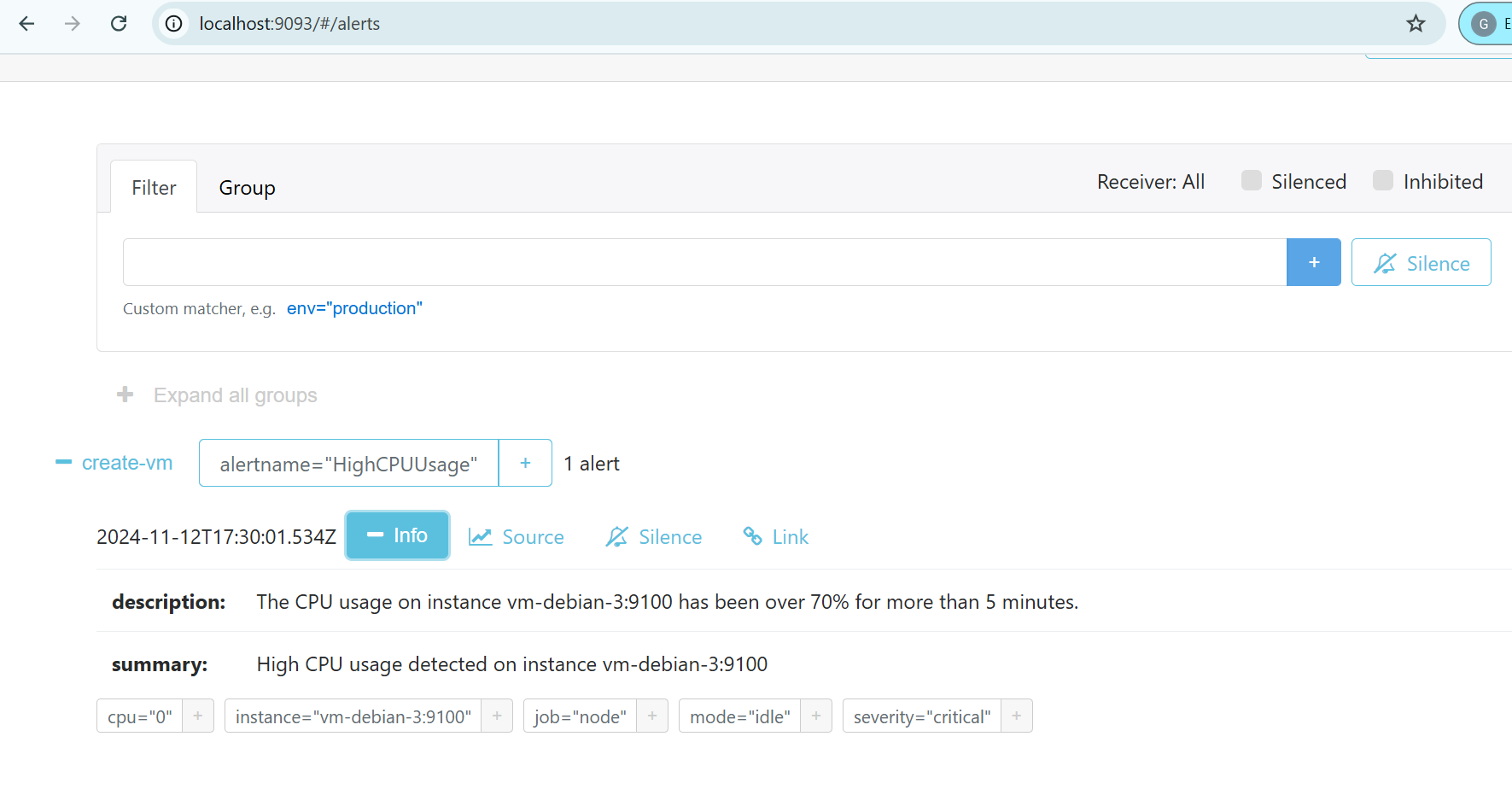
L’interface d’Alertmanager nous permet de constater que l’alerte HighCPUUsage a bien été reçue.
Observons maintenant les logs du conteneur Alertmanager et nous voyons que la récéptionde l’alerte HighCPUUsage envoyée par Prometheus qui déclenche
l’appel à l’API Azure Functions (receiver=create-vm) pour créer une VM sur le cloud Azure (ici après un échec initial).
2024-07-18 09:02:46 ts=2024-07-18T07:02:46.332Z caller=dispatch.go:164 level=debug component=dispatcher msg="Received alert" alert=HighCPUUsage[b709916][active]
2024-07-18 09:02:46 ts=2024-07-18T07:02:46.334Z caller=dispatch.go:516 level=debug component=dispatcher aggrGroup="{}/{alertname=\"HighCPUUsage\"}:{alertname=\"HighCPUUsage\"}" msg=flushing alerts=[HighCPUUsage[b709916][active]]
2024-07-18 09:02:54 ts=2024-07-18T07:02:54.347Z caller=notify.go:848 level=warn component=dispatcher receiver=create-vm integration=webhook[0] aggrGroup="{}/{alertname=\"HighCPUUsage\"}:{alertname=\"HighCPUUsage\"}" msg="Notify attempt failed, will retry later" attempts=1 err="Post \"<redacted>\": dial tcp: lookup tp-cloud-autoscale-vpn.azurewebsites.net on 127.0.0.11:53: server misbehaving"
2024-07-18 09:04:46 ts=2024-07-18T07:04:46.308Z caller=dispatch.go:164 level=debug component=dispatcher msg="Received alert" alert=HighCPUUsage[b709916][active]
2024-07-18 09:05:45 ts=2024-07-18T07:05:45.824Z caller=notify.go:860 level=info component=dispatcher receiver=create-vm integration=webhook[0] aggrGroup="{}/{alertname=\"HighCPUUsage\"}:{alertname=\"HighCPUUsage\"}" msg="Notify success" attempts=2 duration=2m51.482925757s
Retour à une charge CPU normale et suppression de la VM
Maintenant, nous interrompons le test de charge CPU lancé par la commande stress-ng sur le serveur local de notre application.
Nous pouvons constater sur Prometheus que la moyenne horaire de CPU n’a jamais excédé 30% même pendant le pic d’activité généré.
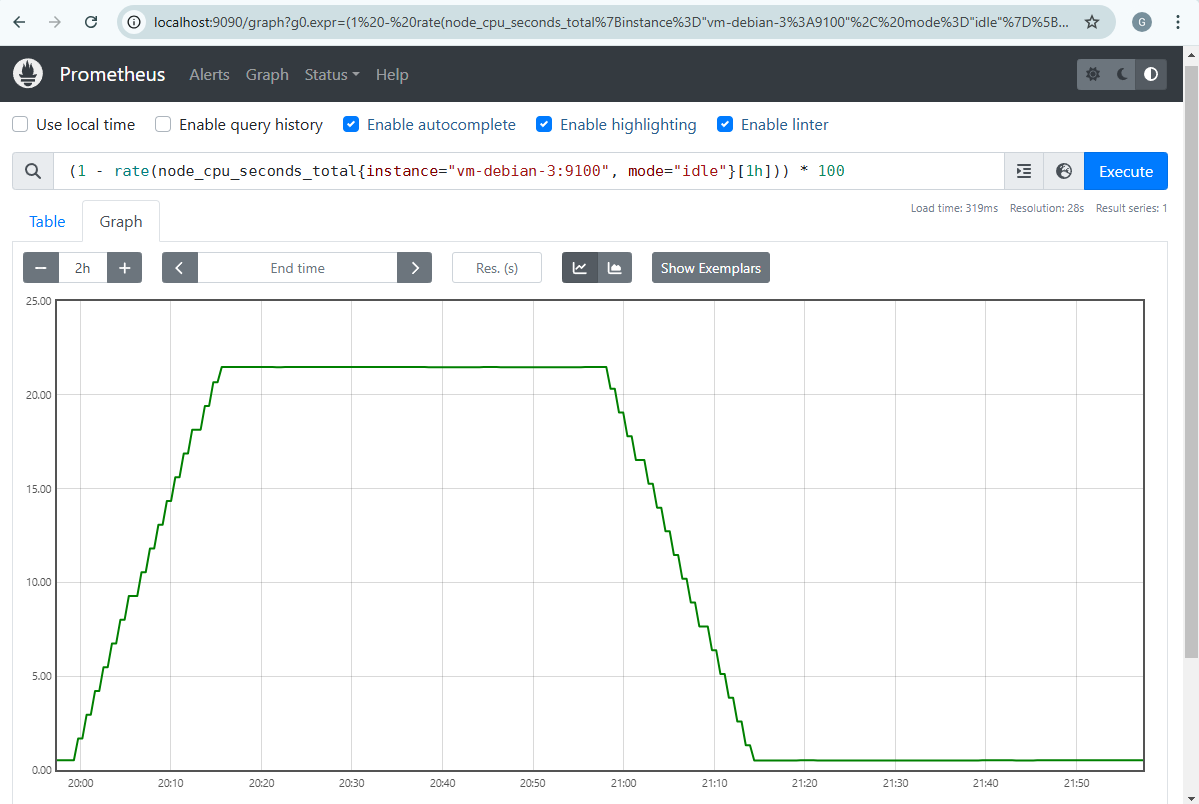
De plus, nous voyons que le pic est bien pris en compte au cours de la dernière heure écoulée pendant une période donnée.
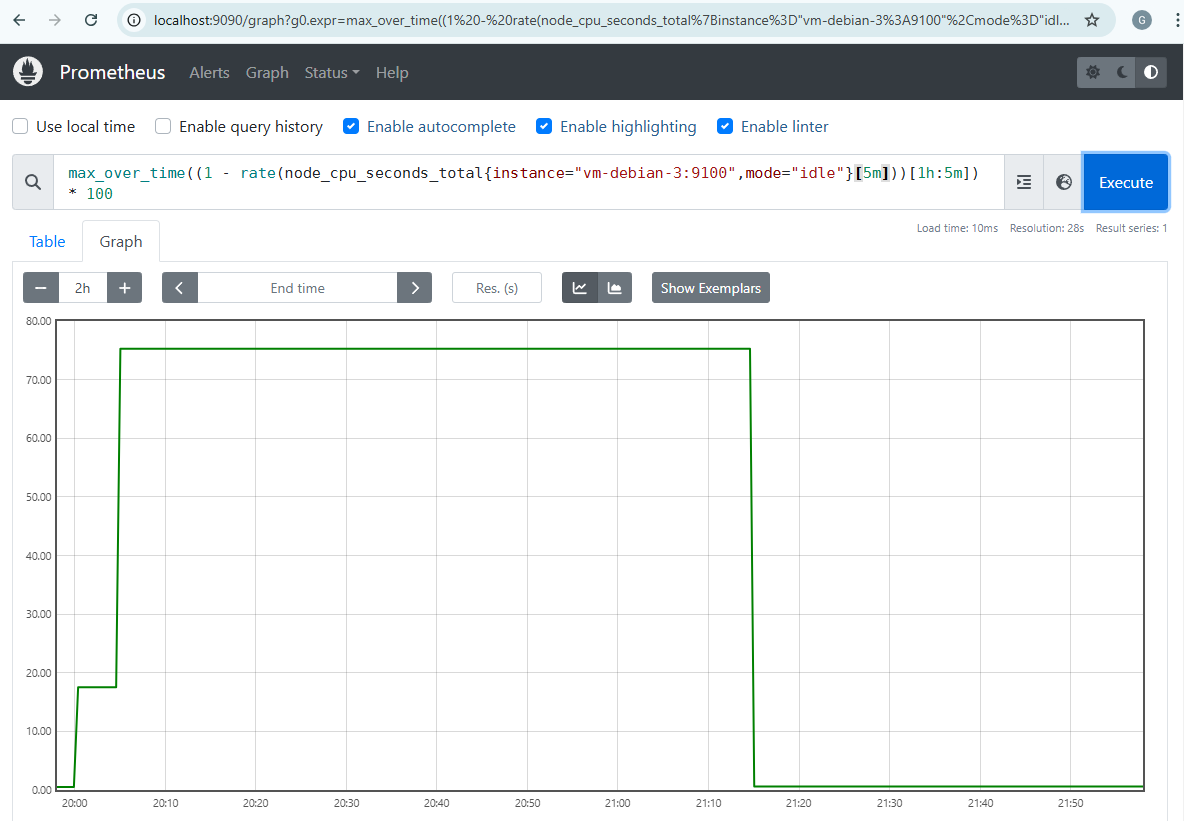
Nous nous retrouvons bien dans les conditions où l’alerte de retour à la normale NormalCPUUsage peut être générée, ce que nous pouvons d’abord constater sur Prometheus.
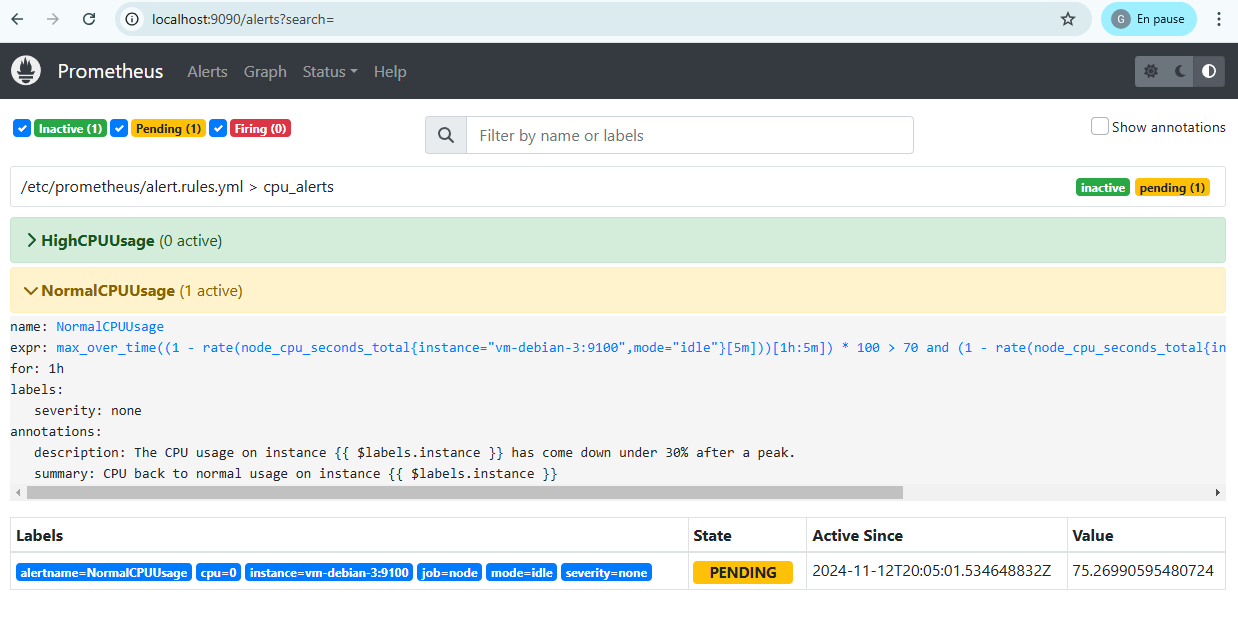
En raison du paramètre for de la configuration Prometheus placé à la valeur 1h, il faut donc attendre cette fois une heure avant que l’alerte ne soit effectivement lancée. Ce délai a été choisi de façon à ne pas surréagir aux variations de CPU et permettre une transition plus fluide entre les différents états.
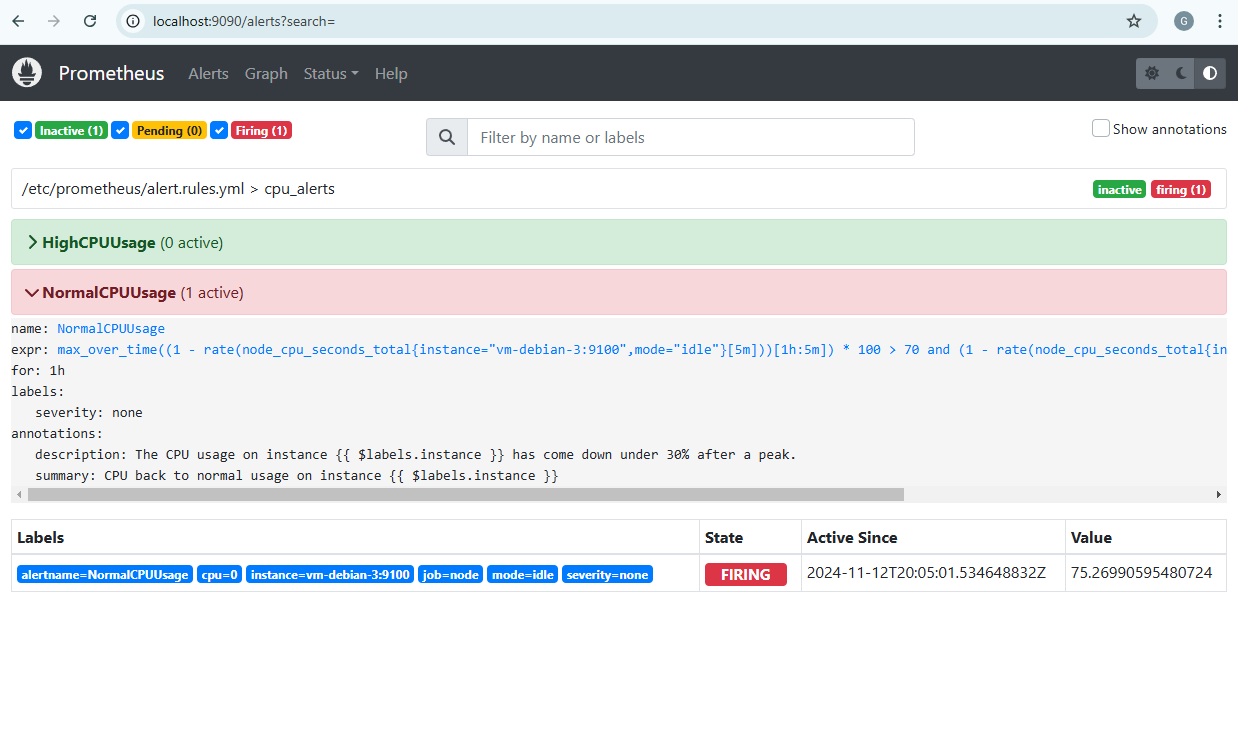
De même que tout à l’heure, l’alerte est bien reçue du côté d’Alertmanager et aboutit à un appel à l’API Azure Functions pour supprimer la VM créée sur Azure (endpoint delete-vm).
2024-07-18 12:13:01 ts=2024-07-18T10:13:01.283Z caller=dispatch.go:164 level=debug component=dispatcher msg="Received alert" alert=NormalCPUUsage[ccec9d5][active]
2024-07-18 12:13:01 ts=2024-07-18T10:13:01.286Z caller=dispatch.go:516 level=debug component=dispatcher aggrGroup="{}/{alertname=\"NormalCPUUsage\"}:{alertname=\"NormalCPUUsage\"}" msg=flushing alerts=[NormalCPUUsage[ccec9d5][active]]
2024-07-18 12:13:09 ts=2024-07-18T10:13:09.298Z caller=notify.go:848 level=warn component=dispatcher receiver=delete-vm integration=webhook[0] aggrGroup="{}/{alertname=\"NormalCPUUsage\"}:{alertname=\"NormalCPUUsage\"}" msg="Notify attempt failed, will retry later" attempts=1 err="Post \"<redacted>\": dial tcp: lookup tp-cloud-autoscale-vpn.azurewebsites.net on 127.0.0.11:53: server misbehaving"
2024-07-18 12:14:35 ts=2024-07-18T10:14:35.741Z caller=notify.go:860 level=info component=dispatcher receiver=delete-vm integration=webhook[0] aggrGroup="{}/{alertname=\"NormalCPUUsage\"}:{alertname=\"NormalCPUUsage\"}" msg="Notify success" attempts=2 duration=1m26.446343094s